Model AI, cadangan mesin inferensi, dan kerangka kerja inferensi terdistribusi terus berkembang dalam arsitektur, kompleksitas, dan skala. Dengan laju perubahan yang cepat, menyebarkan dan mengelola pipa inferensi AI secara efisien yang mendukung kemampuan canggih ini menjadi tantangan kritis.
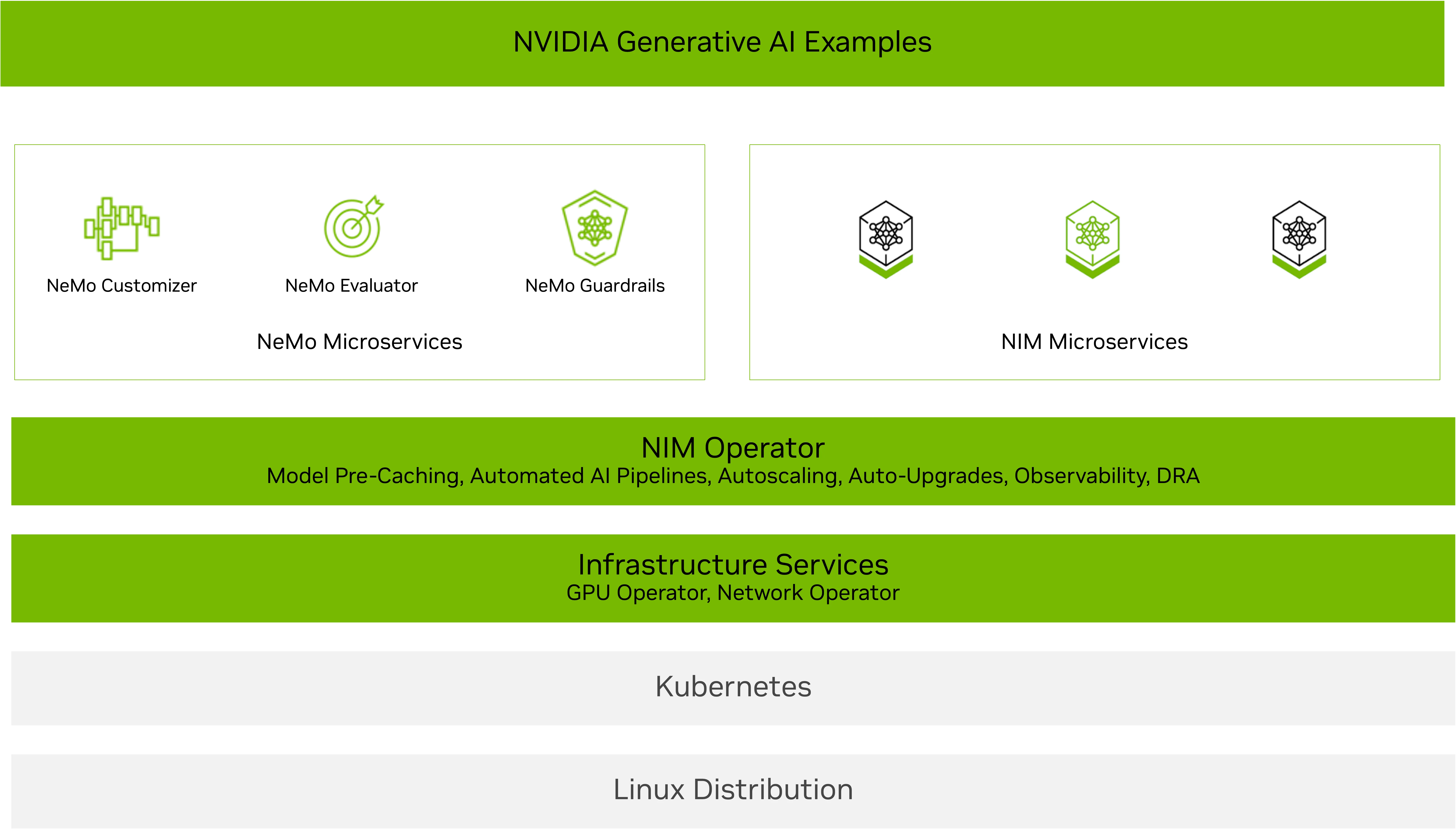
Operator NVIDIA NIM dirancang untuk membantu Anda skala dengan cerdas. Ini memungkinkan administrator kluster Kubernetes untuk mengoperasikan komponen dan layanan perangkat lunak yang diperlukan untuk menjalankan layanan microser nim nim nim untuk model LLM dan multimodal AI terbaru, termasuk penalaran, pengambilan, visi, bicara, biologi, dan banyak lagi.
Rilis terbaru NIM Operator 3.0.0 memperkenalkan kemampuan yang diperluas untuk menyederhanakan dan mengoptimalkan penyebaran layanan mikro NVIDIA NIM dan layanan mikro NVIDIA NEMO di seluruh lingkungan Kubernetes. Operator NIM 3.0.0 mendukung pemanfaatan sumber daya yang efisien dan mengintegrasikan dengan mulus dengan infrastruktur Kubernetes yang ada, termasuk penyebaran KServe.
Pelanggan dan mitra NVIDIA telah menggunakan operator NIM untuk mengelola pipa inferensi secara efisien untuk berbagai aplikasi dan agen AI, termasuk chatbots, agen rag, dan penemuan obat virtual.
NVIDIA baru -baru ini berkolaborasi dengan Red Hat untuk memungkinkan penyebaran NIM di KServe dengan operator NIM. “Red Hat berkontribusi pada operator Open Source Open Source Github Repo untuk memungkinkan penyebaran NIM NIM di Kserve,” kata direktur teknik Red Hat Babak Mozaffari. Fitur ini memungkinkan operator NIM untuk menggunakan NIM Microservices yang mendapat manfaat dari manajemen siklus hidup KServe dan menyederhanakan penyebaran NIM yang dapat diskalakan menggunakan layanan NIM. Dukungan kserve asli di operator NIM juga memungkinkan pengguna untuk mendapatkan manfaat dari cache NIM dan leverage yang dipercayai seperti NEMO.
Posting ini menjelaskan kemampuan baru dalam rilis NIM Operator 3.0.0, termasuk:
Penyebaran NIM Fleksibel: Kompatibel Multi-Llm dan Multi-Node
Operator NIM 3.0.0 menambahkan dukungan untuk penyebaran NIM yang mudah dan cepat. Anda dapat menggunakannya dengan NIM khusus domain-seperti yang untuk biologi, ucapan, atau pengambilan-atau berbagai opsi penyebaran NIM, termasuk multi-llm yang kompatibel, atau multi-node.
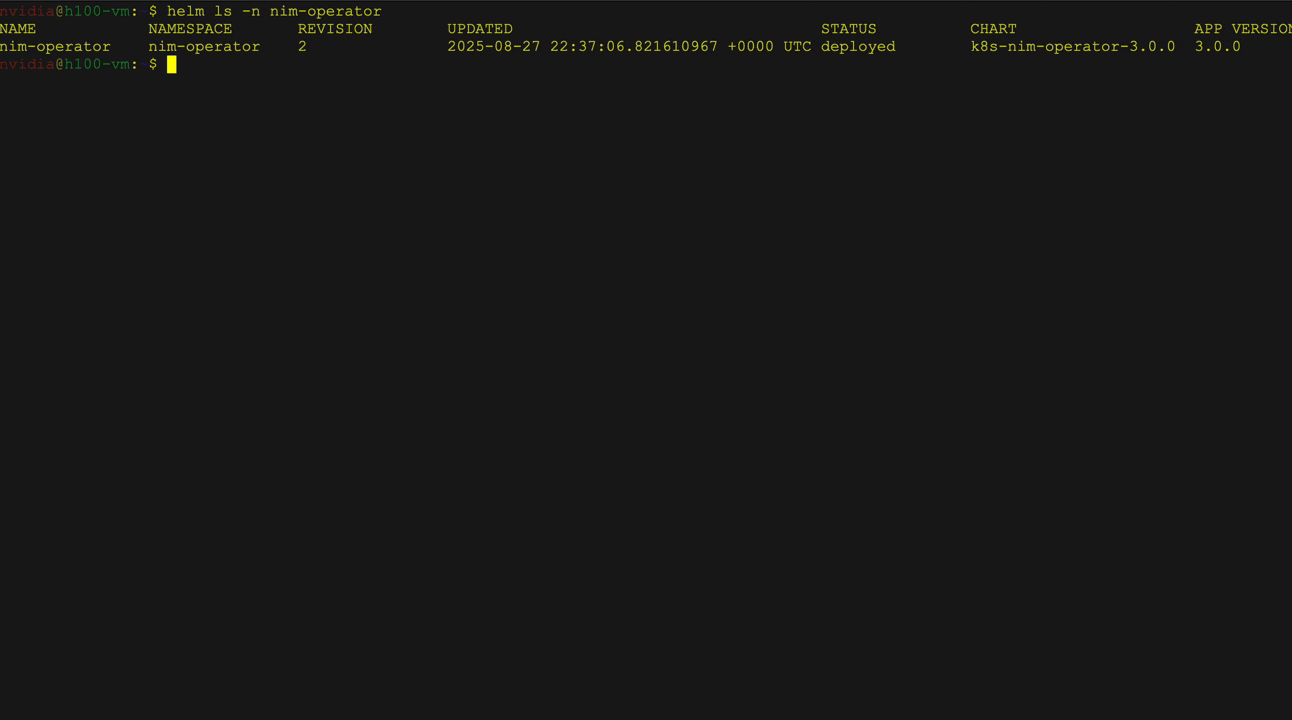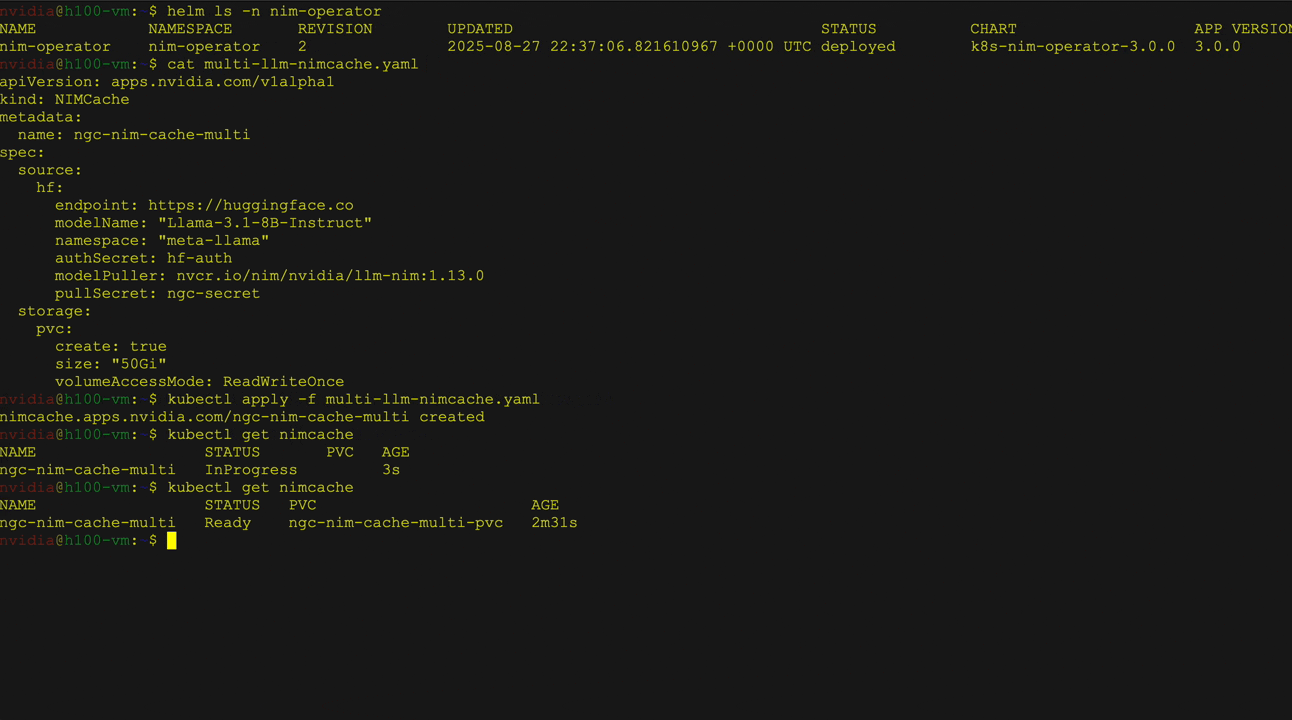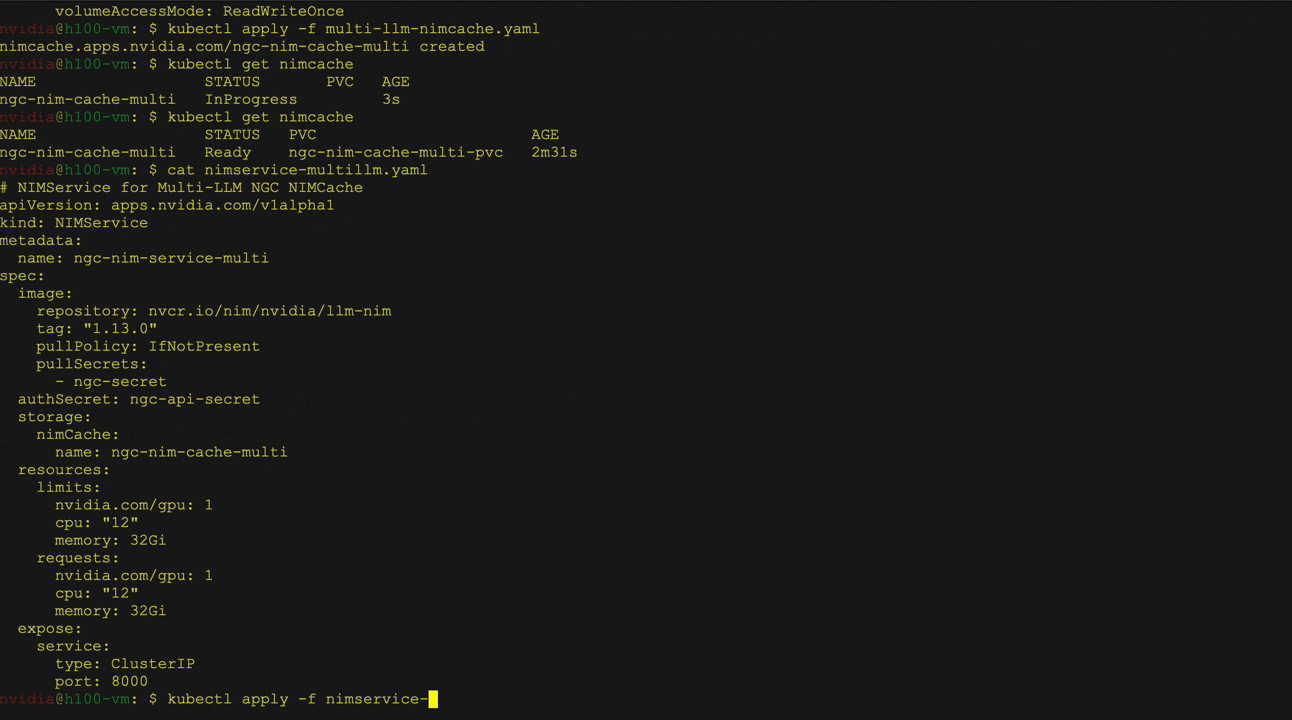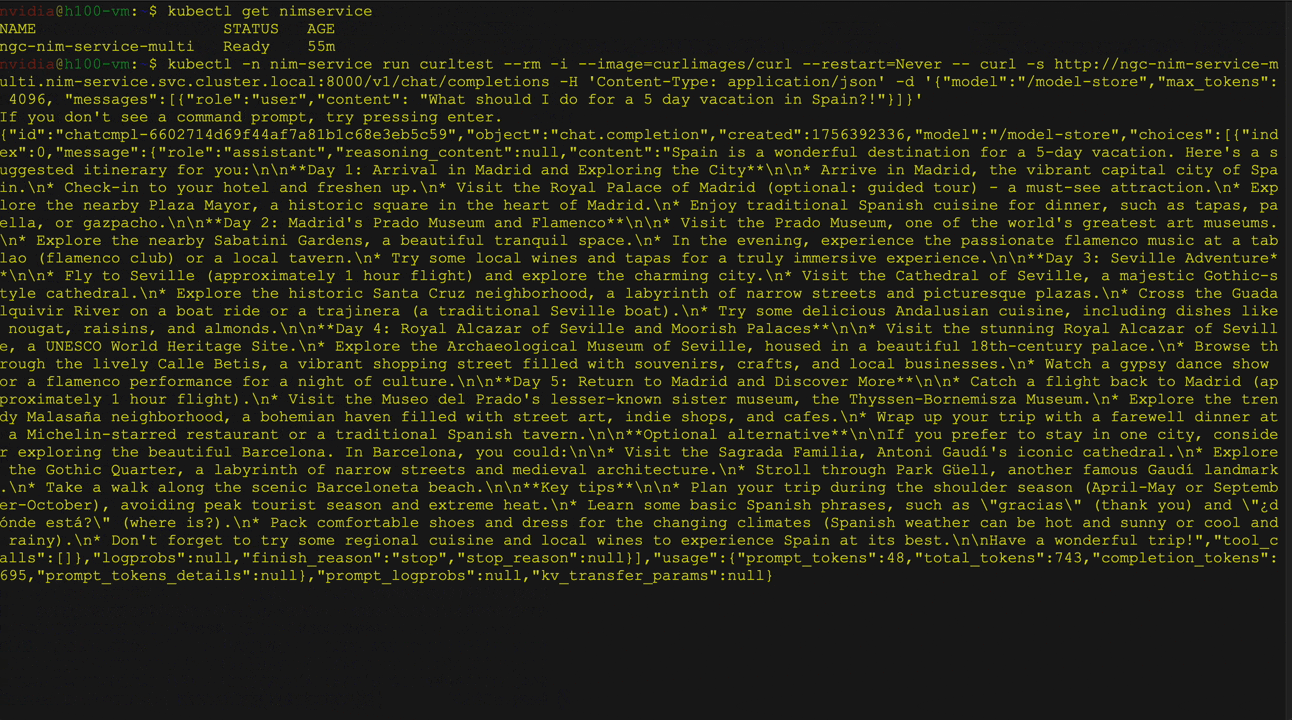
- Penyebaran NIM yang kompatibel dengan multi-llm: Menyebarkan beragam model dengan bobot khusus dari sumber seperti NVIDIA NGC, memeluk wajah, atau penyimpanan lokal. Gunakan Definisi Sumber Daya Kustom NIM Cache (CRD) untuk mengunduh bobot ke PVC dan Layanan NIM CRD untuk mengelola penyebaran, penskalaan, dan masuk.
- Penyebaran NIM multi-node Mengatasi tantangan menggunakan LLM besar yang tidak dapat muat pada satu GPU atau perlu berjalan pada beberapa GPU dan berpotensi pada beberapa node. Operator NIM mendukung caching untuk penyebaran NIM multi-node menggunakan NIM Cache CRD, dan menyebarkannya menggunakan layanan NIM CRD pada Kubernetes dengan Leaderworkersets (LWS).
Perhatikan bahwa penyebaran NIM multi-node tanpa GPudirect RDMA dapat mengakibatkan sering restart dari pemimpin LWS dan pod pekerja karena model waktu pemuatan shard. Menggunakan konektivitas jaringan cepat seperti IPOIB atau ROCE sangat disarankan dan dapat dengan mudah dikonfigurasi melalui operator jaringan NVIDIA.
Gambar 2 menunjukkan penyebaran model bahasa besar (LLM) dari perpustakaan wajah pemeluk pada kubernet menggunakan operator NVIDIA NIM sebagai penyebaran NIM multi-llm. Ini secara khusus menunjukkan menggunakan model instruksi LLAMA 3 8B, termasuk layanan dan verifikasi status pod, diikuti oleh a curl Perintah untuk mengirim permintaan ke Layanan.
Pemanfaatan GPU yang efisien dengan DRA
DRA adalah fitur kubernet built-in yang menyederhanakan manajemen GPU dengan mengganti plugin perangkat tradisional dengan pendekatan yang lebih fleksibel dan dapat diperluas. DRA memungkinkan pengguna untuk mendefinisikan kelas perangkat GPU, meminta GPU berdasarkan kelas -kelas tersebut, dan memfilternya sesuai dengan beban kerja dan kebutuhan bisnis.
Operator NIM 3.0.0 mendukung DRA di bawah Pratinjau Teknologi dengan mengonfigurasi ResourceClaim dan ResourceClaimTemplate di NIM Pod melalui NIM Service CRD dan NIM Pipeline CRD. Anda dapat membuat dan melampirkan klaim Anda sendiri atau membiarkan operator NIM membuat dan mengelolanya secara otomatis.
Operator NIM DRA mendukung:
- GPU penuh dan penggunaan MIG
- Berbagi GPU Melalui pengiralan waktu dengan menetapkan klaim yang sama untuk beberapa layanan NIM
Catatan: Fitur ini saat ini tersedia sebagai pratinjau teknologi, dengan dukungan penuh segera tersedia.
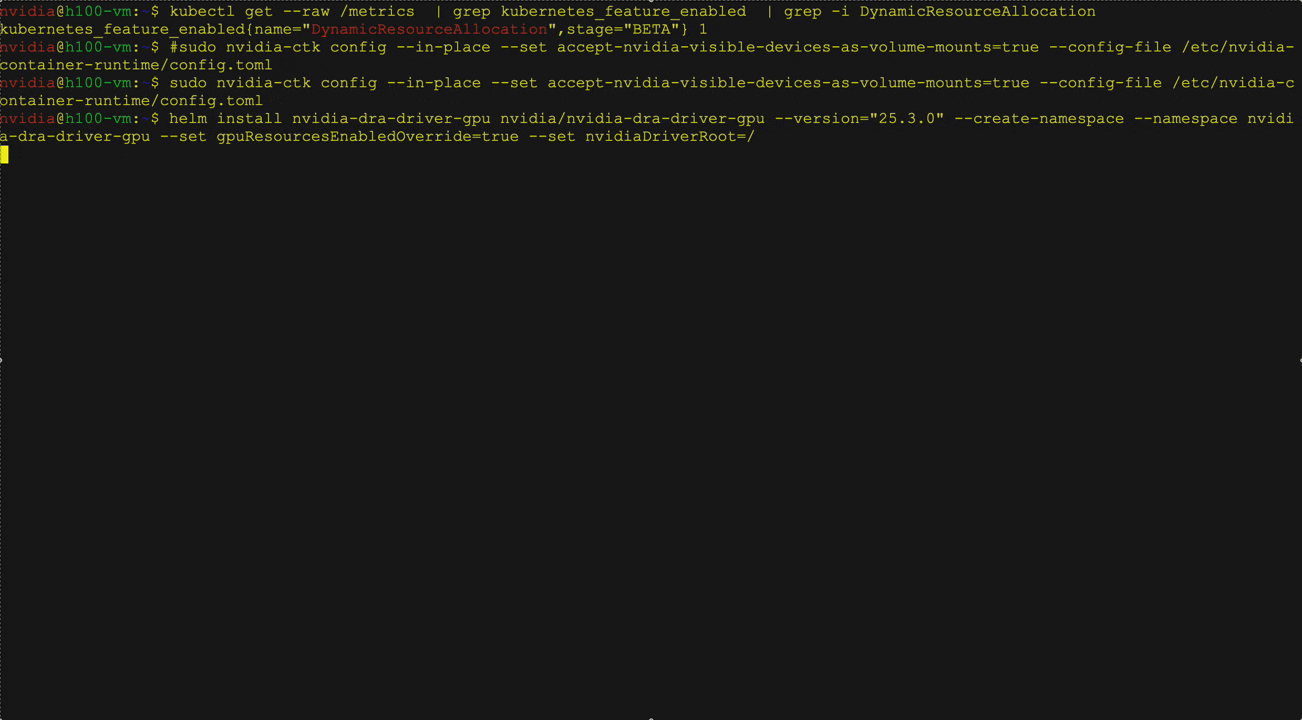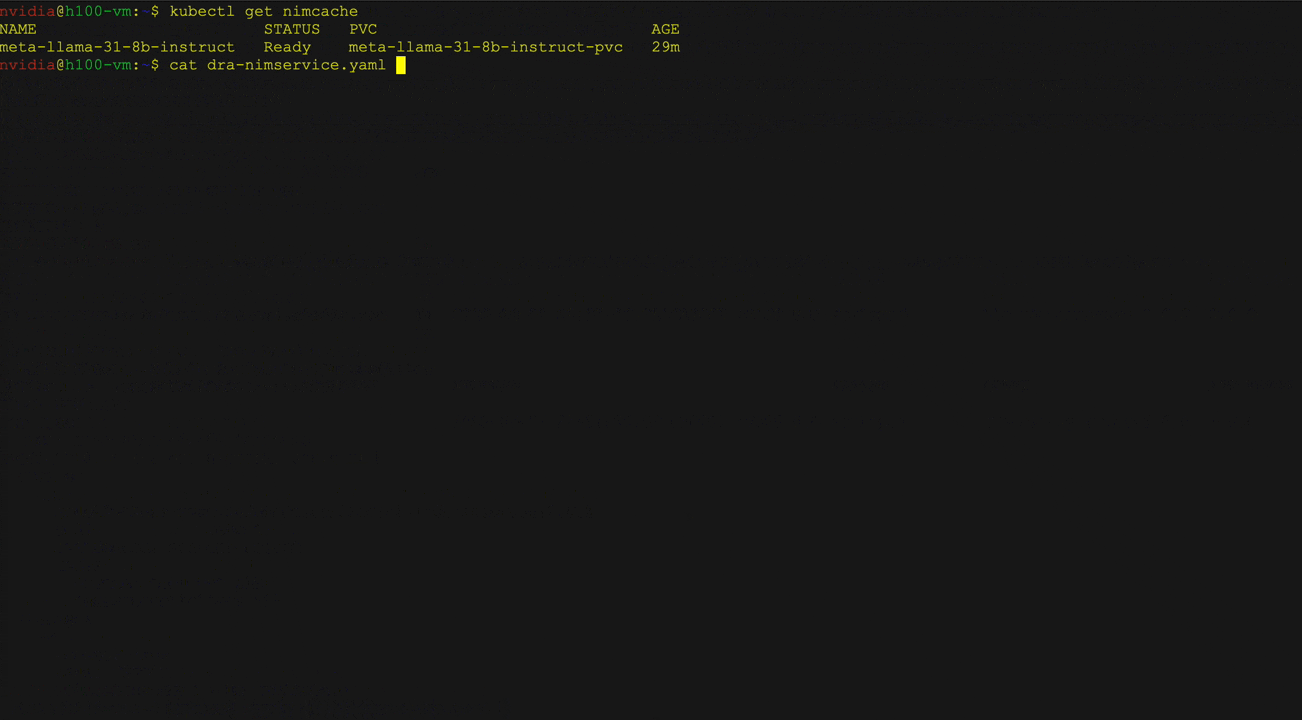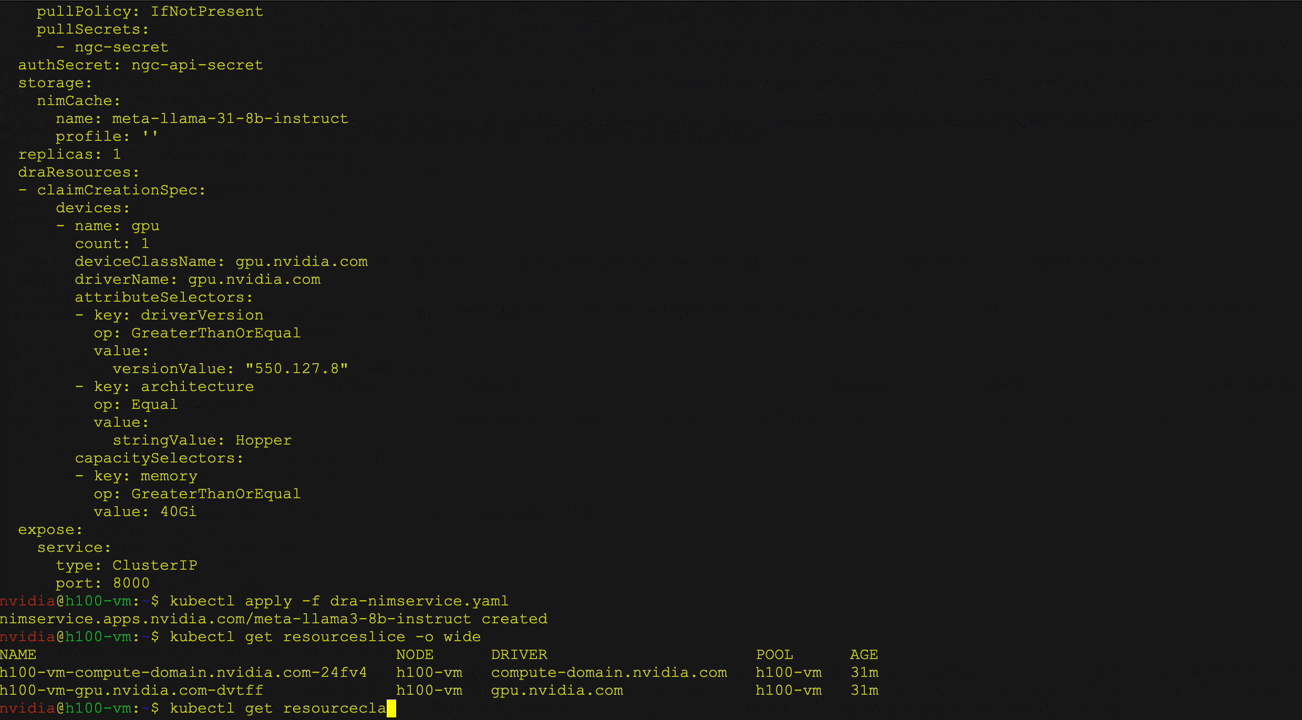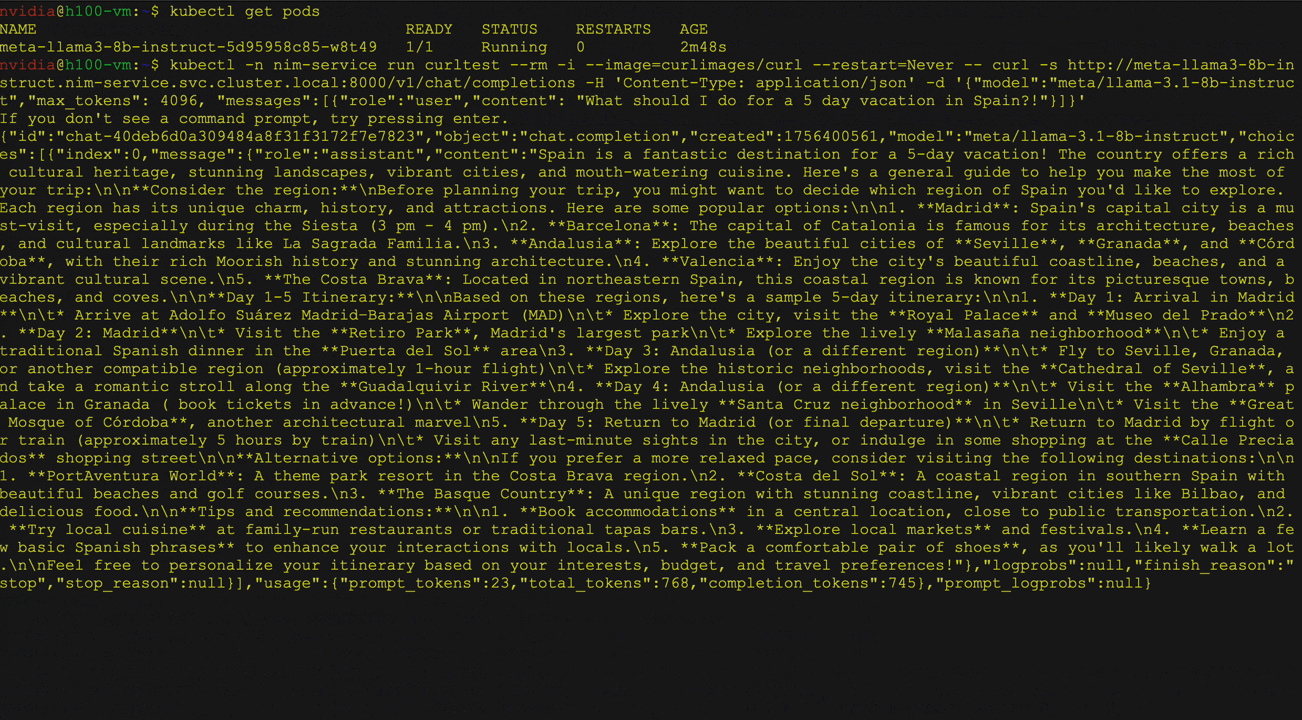
Gambar 3 menunjukkan penyebaran LLAMA 3 8B Instruksi NIM menggunakan Kubernetes DRA dengan operator NIM. Pengguna dapat menentukan klaim sumber daya dalam layanan NIM untuk meminta atribut perangkat keras tertentu seperti arsitektur dan memori GPU, dan berinteraksi dengan LLM yang digunakan menggunakan curl.
Penempatan mulus di kserve
KServe adalah platform pelayanan inferensi open source yang diadopsi secara luas yang digunakan oleh banyak mitra dan pelanggan. Operator NIM 3.0.0 mendukung penyebaran mentah dan tanpa server di KServe dengan mengonfigurasi sumber daya kustom InferencesService untuk mengelola penyebaran, peningkatan, dan autoscaling NIM. Operator NIM menyederhanakan proses penyebaran dengan secara otomatis mengkonfigurasi semua variabel lingkungan dan sumber daya yang diperlukan dalam CRDService CRD.
Integrasi ini memberikan dua manfaat tambahan:
- Caching cerdas dengan cache NIM untuk mengurangi waktu inferensi awal dan latensi autoscaling, menghasilkan penyebaran yang lebih cepat dan lebih responsif.
- Nemo Microservices mendukung evaluasi, pagar pembatas, dan penyesuaian untuk meningkatkan sistem AI untuk latensi, akurasi, biaya, dan kepatuhan.
Gambar 4 menunjukkan penyebaran LLAMA 3.2 1B Instruksi NIM pada KServe menggunakan operator NIM. Dua metodologi penyebaran yang berbeda ditampilkan: RawDeployment dan Serverless. Penyebaran tanpa server menggabungkan fungsionalitas autoscaling melalui anotasi K8S. Kedua strategi menggunakan perintah curl untuk menguji respons NIM.

Mulailah menskalakan inferensi AI dengan operator NIM 3.0.0
NVIDIA NIM Operator 3.0.0 membuat penyusutan inferensi AI yang dapat diskalakan lebih mudah dari sebelumnya. Apakah Anda bekerja dengan penyebaran NIM multi-llm yang kompatibel atau multi-node, mengoptimalkan penggunaan GPU dengan DRA, atau menggunakan KServe, rilis ini memungkinkan Anda untuk membangun aplikasi AI berkinerja tinggi, fleksibel, dan terukur.
Dengan mengotomatiskan manajemen penyebaran, penskalaan, dan siklus hidup baik NVIDIA NIM dan NVIDIA NEMO Microservices, Operator NIM memudahkan tim perusahaan untuk mengadopsi alur kerja AI. Upaya ini selaras dengan membuat alur kerja AI mudah digunakan dengan cetak biru Nvidia AI, memungkinkan pergerakan cepat untuk produksi. Operator NIM adalah bagian dari NVIDIA AI Enterprise, memberikan dukungan perusahaan, stabilitas API, dan penambalan keamanan proaktif.
Mulailah melalui NGC atau dari repo Open Source Github NVIDIA/K8S-NIM-Operator. Untuk pertanyaan teknis tentang instalasi, penggunaan, atau masalah, mengajukan masalah pada repo Github NVIDIA/K8S-NIM-Operator.
Menyebarkan inferensi AI yang dapat diskalakan dengan operator NVIDIA NIM 3.0.0