Rilis 25.08 Rapids terus mendorong batas menuju membuat ilmu data yang dipercepat lebih mudah diakses dan diukur dengan penambahan beberapa fitur baru, termasuk:
- Dua alat profil baru untuk pemecahan masalah CUML.Accel Code
- Dukungan untuk data yang lebih besar dan lebih kompleks di mesin GPU Polar
- Dukungan Algoritma Baru di CUML dan CUML.Accel
- Pembaruan Dukungan Versi CUDA
Pelajari lebih lanjut tentang fitur baru di bawah ini.
Rilis 25.08 membawa penambahan dua opsi profil baru ke cuml.accel. Mirip dengan profiler yang sebelumnya dirilis untuk cudf.panda, fitur profil baru ini membantu pengguna memahami operasi mana yang dipercepat oleh CUML pada GPU, yang kembali berjalan pada CPU, dan berapa lama operasi ini berlangsung. Ini dapat berguna bagi pengguna yang mencoba memahami kemacetan kinerja saat ini dalam alur kerja pembelajaran mesin mereka.
Pertama, kami memperkenalkan profiler tingkat fungsi. Profiler ini menunjukkan kepada pengguna semua operasi dalam skrip atau sel tertentu yang dijalankan pada GPU vs CPU. Ini juga menunjukkan jumlah waktu yang diambil masing -masing fungsi pada masing -masing.
Ada dua cara untuk menggunakan profiler tingkat fungsi. Jika menjalankan notebook Jupyter atau Ipython, pengguna dapat menelepon %%cuml.accel.profile setelah cuml.accel telah dimuat dan profil seluruh sel:
%%cuml.accel.profile
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100)
# Fit and predict on GPU
ridge = Ridge(alpha=1.0)
ridge.fit(X, y)
ridge.predict(X)
# Retry, using an unsupported hyperparameter
ridge = Ridge(positive=True)
ridge.fit(X, y)
ridge.predict(X)
Output sel ini berisi hasil profil:
cuml.accel profile
┏━━━━━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━┓
┃ Function ┃ GPU calls ┃ GPU time ┃ CPU calls ┃ CPU time ┃
┡━━━━━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━┩
│ Ridge.fit │ 1 │ 141.2ms │ 1 │ 3ms │
│ Ridge.predict │ 1 │ 31.5ms │ 1 │ 97.3µs │
├───────────────┼───────────┼──────────┼───────────┼──────────┤
│ Total │ 2 │ 172.7ms │ 2 │ 3.1ms │
└───────────────┴───────────┴──────────┴───────────┴──────────┘
Not all operations ran on the GPU. The following functions required CPU fallback for the following reasons:
* Ridge.fit
- `positive=True` is not supported
* Ridge.predict
- Estimator not fit on GPU
Profiler tingkat fungsi juga dapat dipanggil pada skrip Python menggunakan --profile Bendera dari CLI:
python -m cuml.accel --profile script.py
Profiler kedua adalah profiler tingkat garis, menunjukkan kepada pengguna di mana setiap bagian kode dieksekusi garis demi garis. Seperti profiler tingkat fungsi, profiler tingkat garis dapat dipanggil dalam buku catatan dengan %%cuml.accel.line_profile.
%%cuml.accel.line_profile
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100)
# Fit and predict on GPU
ridge = Ridge(alpha=1.0)
ridge.fit(X, y)
ridge.predict(X)
# Retry, using an unsupported hyperparameter
ridge = Ridge(positive=True)
ridge.fit(X, y)
ridge.predict(X)
cuml.accel line profile
┏━━━━┳━━━┳━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ # ┃ N ┃ Time ┃ GPU % ┃ Source ┃
┡━━━━╇━━━╇━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ 1 │ 1 │ - │ - │ from sklearn.linear_model import Ridge │
│ 2 │ 1 │ - │ - │ from sklearn.datasets import make_regression │
│ 3 │ │ │ │ │
│ 4 │ │ │ │ │
│ 5 │ 1 │ 1.1ms │ - │ X, y = make_regression(n_samples=100) │
│ 6 │ │ │ │ │
│ 7 │ │ │ │ │
│ 8 │ │ │ │ # Fit and predict on GPU │
│ 9 │ 1 │ - │ - │ ridge = Ridge(alpha=1.0) │
│ 10 │ 1 │ 174.2ms │ 99.0 │ ridge.fit(X, y) │
│ 11 │ 1 │ 5.2ms │ 99.0 │ ridge.predict(X) │
│ 12 │ │ │ │ │
│ 13 │ │ │ │ │
│ 14 │ │ │ │ # Retry, using an unsupported hyperparameter │
│ 15 │ 1 │ - │ - │ ridge = Ridge(positive=True) │
│ 16 │ 1 │ 4.5ms │ 0.0 │ ridge.fit(X, y) │
│ 17 │ 1 │ 172.7µs │ 0.0 │ ridge.predict(X) │
│ 18 │ │ │ │ │
└────┴───┴─────────┴───────┴──────────────────────────────────────────────┘
Ran in 185.6ms, 96.4% on GPU
Profiler garis juga dapat dipanggil melalui --line-profile Bendera dari baris perintah:
python -m cuml.accel --line-profile script.py
Dengan kemampuan profil baru ini, cuml.accel Memberikan lebih banyak alat untuk membuat kode pembelajaran mesin yang mempercepat dan men -debugging lebih mudah.
Proses data yang lebih besar dan lebih kompleks dengan mesin GPU POLAR yang ditenagai oleh NVIDIA CUDF
Bekerja dengan set data yang lebih besar dari memori GPU dengan pelaksana streaming default baru
Mode eksekusi streaming yang diperkenalkan sebagai fitur eksperimental di 25.06 sekarang merupakan default di mesin GPU POLAR. Eksekutor baru ini mengambil keuntungan dari partisi data untuk memungkinkan dataset yang jauh lebih besar dari VRAM (memori GPU) diproses secara efisien. Pelaksana streaming masih dapat kembali ke eksekusi dalam memori untuk setiap operasi yang tidak didukung, tetapi pada rilis 25.08, eksekusi streaming mendukung hampir semua operator yang didukung untuk eksekusi GPU dalam memori. Ini membuka kinerja substansial dan peningkatan skalabilitas.
Untuk set data yang lebih kecil, menggunakan mode eksekusi streaming pada GPU tunggal menimbulkan overhead kinerja yang sangat kecil jika dibandingkan dengan menggunakan mesin dalam memori. Namun, ketika ukuran dataset tumbuh dan mulai melebihi memori GPU, pelaksana streaming memberikan percepatan besar dibandingkan dengan mesin dalam memori.
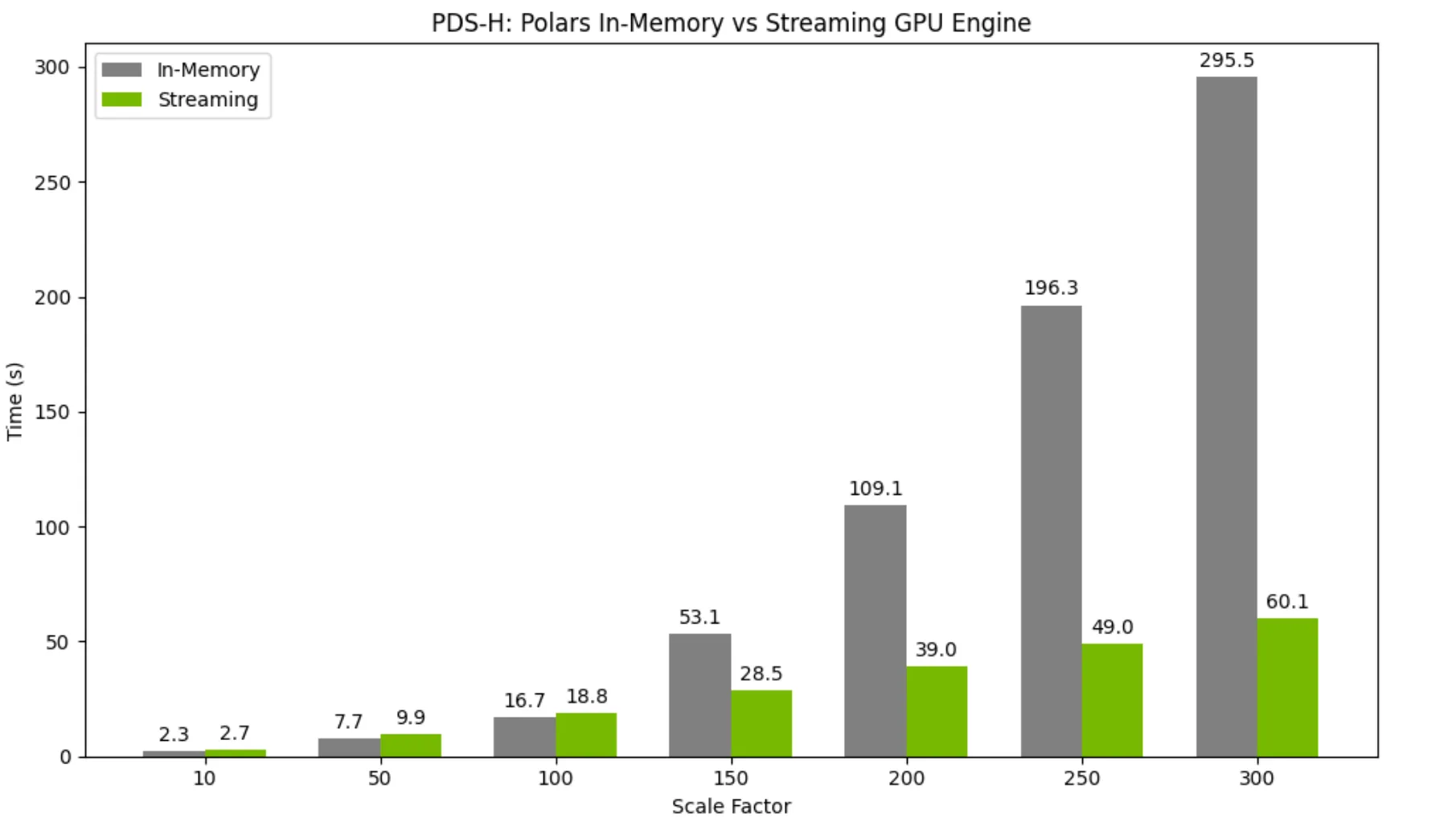
Untuk informasi lebih lanjut tentang pelaksana streaming GPU Polar, kunjungi dokumentasi kami.
Simpan data kompleks seperti struct dan operasi string di GPU
Mesin GPU Polar sekarang mendukung data struct di kolom. Sebelumnya, setiap operasi yang melibatkan struct akan kembali ke eksekusi CPU, tetapi dengan rilis terbaru semua operasi ini sekarang diperkuat GPU untuk peningkatan kinerja:
>>> import polars as pl
... ratings = pl.LazyFrame(
... {
... "Movie": ["Cars", "IT", "ET", "Cars", "Up", "IT", "Cars", "ET", "Up", "ET"],
... "Theatre": ["NE", "ME", "IL", "ND", "NE", "SD", "NE", "IL", "IL", "SD"],
... "Avg_Rating": [4.5, 4.4, 4.6, 4.3, 4.8, 4.7, 4.7, 4.9, 4.7, 4.6],
... "Count": [30, 27, 26, 29, 31, 28, 28, 26, 33, 26],
... }
... )
... ratings.select(pl.col("Theatre").value_counts()).collect(engine=pl.GPUEngine(raise_on_fail=True))
...
shape: (5, 1)
┌───────────┐
│ Theatre │
│ --- │
│ struct[2] │
╞═════════==╡
│ {"NE",3} │
│ {"ND",1} │
│ {"ME",1} │
│ {"SD",2} │
│ {"IL",3} │
└───────────┘
Selain itu, mesin GPU POLAR sekarang mendukung serangkaian operator string yang diperluas secara substansial, misalnya:
>>> ldf = pl.LazyFrame({"foo": [1, None, 2]})
>>> ldf.select(pl.col("foo").str.join("-")).collect(engine=gpu_engine)
shape: (1, 1)
┌─────┐
│ foo │
│ --- │
│ str │
╞═════╡
│ 1-2 │
└─────┘
>>> ldf = pl.LazyFrame({
... "lines": [
... "I Like\nThose\nOdds",
... "This is\nThe Way",
... ]
... })
... ldf.with_columns(
... pl.col("lines").str.extract(r"(T\w+)", 1).alias("matches"),
... ).collect(engine=pl.GPUEngine(raise_on_fail=True))
...
shape: (2, 2)
┌─────────┬──────┐
│ lines ┆ matches │
│ --- ┆ --- │
│ str ┆ str │
╞═════════╪══════╡
│ I Like ┆ Those │
│ Those ┆ │
│ Odds ┆ │
│ This is ┆ This │
│ The Way ┆ │
└─────────┴──────┘
Perluasan dukungan tipe data semakin memperkuat kemampuan mesin GPU POLAR, mempercepat pengiriman fungsionalitas pengguna akhir yang paling umum.
Algoritma baru didukung dalam cuml: embedding spektral, linearsvc, linearsvr, dan kernelridge
Dengan rilis 25.08, CUML telah menambahkan algoritma embedding spektral untuk pengurangan dimensi dan pembelajaran berlipat ganda. Embedding spektral adalah pendekatan yang menggunakan nilai eigen dan vektor eigen dari grafik kesamaan untuk menanamkan data dimensi tinggi ke dalam ruang dimensi yang lebih rendah.
API untuk algoritma embedding spektral baru dalam CUML cocok dengan implementasi embedding spektral di scikit-learn:
from cuml.manifold import SpectralEmbedding
import cupy as cp
from sklearn.datasets import fetch_openml
# (70000, 784) -> (70000, 2)
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist.data, mnist.target.astype(int)
spectral = SpectralEmbedding(n_components=2, n_neighbors=None, random_state=42)
embedding = spectral.fit_transform(cp.asarray(X, order='C', dtype=cp.float32))
Selain itu, CUML.Accel sekarang mempercepat beberapa algoritma baru dengan perubahan kode nol. LinearSVC dan LinearSVR Estimator ditambahkan dalam rilis 25.08, yang berarti bahwa semua estimator dalam keluarga mesin vektor dukungan sekarang menjadi bagian dari CUML.Accel.
Kernelridge juga ditambahkan ke CUML.Accel, membawa algoritma regresi populer lainnya di bawah payung perubahan kode nol.
Untuk informasi lebih lanjut tentang algoritma yang didukung hari ini, lihat dokumentasi lengkap kami.
Dukungan Dukungan Cuda 11
Dimulai dengan rilis 25.08, kami menjatuhkan dukungan untuk CUDA 11, yang mencakup semua kontainer, paket yang diterbitkan, dan kemampuan untuk membangun dari sumber. Pengguna yang ingin terus menjalankan CUDA 11 Mei Pin ke Rapids versi 25.06.
Kunjungi dokumentasi Rapids untuk mempelajari lebih lanjut.
Kesimpulan
Rilis Nvidia Rapids 25.08 menawarkan lompatan ke depan dalam mempercepat dan mengoptimalkan alur kerja ilmu data. Dengan diperkenalkannya CUML.Accel Profiler, pengembang sekarang memiliki alat yang kuat untuk mendiagnosis dan meningkatkan kinerja kode pembelajaran mesin mereka. Pembaruan untuk mesin GPU POLAR seperti pelaksana streaming dan dukungan tipe data yang diperluas memungkinkan pemrosesan yang efisien dari set data yang besar, meningkatkan skalabilitas dan kinerja. Selain itu, dimasukkannya algoritma baru dalam CUML lebih lanjut merampingkan ekosistem pembelajaran mesin. Perkembangan ini secara kolektif berkontribusi untuk membuat ilmu data yang dipercepat lebih mudah diakses dan efisien bagi pengguna. Untuk menyelam lebih dalam ke semua fitur dan peningkatan baru, pastikan untuk mengunjungi dokumentasi Rapids.
Kami menyambut umpan balik Anda di GitHub. Anda juga dapat bergabung dengan 3.500 anggota komunitas Rapids Slack untuk berbicara pemrosesan data yang dipercepat GPU.
Jika Anda baru mengenal Rapids, periksa sumber daya ini untuk memulai dan mengambil alur kerja Ilmu Data Akselerasi kami dengan Nol Kode Perubahan Kursus secara gratis. Untuk mempelajari lebih lanjut tentang ilmu data yang dipercepat, jelajahi jalur pembelajaran DLI kami dan mendaftar dalam kursus langsung, seperti praktik terbaik dalam rekayasa fitur untuk data tabel dengan akselerasi GPU.