Yang terbaru untuk devs dari made by google, pembaruan ke Gemini di Android Studio, ditambah androidify baru: episode musim panas kami dari The Android Show
Diposting oleh Matthew McCullough – VP manajemen produk, pengembang Android dalam ekosistem yang dinamis dan kompleks ini, komitmen kami adalah untuk …
Deploying large language models (LLMs) poses a challenge in optimizing inference efficiency. In particular, cold start delays—where models take significant time to load into GPU memory—can impact user experience and scalability. Increasingly, complex production environments highlight the need for efficient model loading. These models often require tens to hundreds of gigabytes of memory, causing latency and resource challenges when scaling to meet unpredictable demand. Cold start delays impact end-user experience and operational efficiency.
This post introduces the NVIDIA Run:ai Model Streamer, an open source Python SDK designed to mitigate these issues by concurrently reading model weights from storage and streaming them directly into GPU memory. We benchmarked it against the vLLM default Hugging Face (HF) Safetensors Loader and CoreWeave Tensorizer on local SSDs and Amazon S3.
The experiments explained in this post show that the NVIDIA Run:ai Model Streamer significantly reduces model loading times, lowering cold start latency even in cloud environments. It also remains compatible with the Safetensor format, avoiding weight conversion. Our findings emphasize storage choice and concurrent streaming for efficient LLM deployment. Specifically, to improve inference performance, use the NVIDIA Run:ai Model Streamer to reduce cold-start latency, saturate your storage throughput, and accelerate time-to-inference.
How is a model loaded to a GPU for inference?
To provide some background information, this section explains the two main steps involved in loading a machine learning model into GPU memory for inference: reading weights from storage into CPU memory, and transferring them to the GPU. Understanding this process is key to optimizing inference latency, especially in large-scale or cloud-based deployments.
Reading weights from storage to CPU memory: The model’s weights are loaded from storage into CPU memory. Weights can be in various formats such as .pt, .h5, and .safetensors, or in custom formats; storage can be local, cluster-wide, or in the cloud. Note that the .safetensors format is used for the purposes of this post due to its wide adoption. However, other formats may be used elsewhere.
Moving the model to GPU: The model’s parameters and relevant tensors are transferred to GPU memory.
Loading models from cloud-based storage such as Amazon S3 often involves an extra step: the weights are first downloaded to local disk before being moved into CPU and then GPU memory.
Traditionally, these steps occur sequentially, making model loading times one of the most significant bottlenecks when scaling inference.
How does the Model Streamer work?
Model Streamer is an SDK with a high-performance C++ backend designed to accelerate model loading into GPUs from various storage sources (for example, network file systems, cloud, local disks, and so on). It uses multiple threads to read tensors concurrently from a file in object or file storage, to a dedicated buffer in the CPU memory. Each tensor has an identifier, enabling simultaneous reading and transfer: while some tensors are read from storage to CPU, others are moved from CPU to GPU.
The tool takes full advantage of the fact that GPU and CPU have separate subsystems. GPUs access CPU memory directly through PCIe without CPU intervention, allowing real-time overlap of storage reads and memory transfers. Experiments were run on an AWS g5.12xlarge instance with NVIDIA A10G GPUs and 2nd Gen AMD EPYC CPUs—offering balanced architecture for high-throughput parallel data handling.
Key features of the Model Streamer include:
Concurrency: Multiple threads read model weight files in parallel, including support for splitting large tensors.
Balanced workload for reading: Work is distributed based on tensor size to saturate storage bandwidth.
Support for multiple storage types: Works with SSDs, remote storage, and cloud object stores like S3.
No tensor format conversion: Supports Safetensors natively, avoiding conversion overhead.
Easy integration: Offers a Python API and an iterator similar to Safetensors but with concurrent background reading. Integrates easily with inference engines like vLLM and TGI.
For more details about setup and usage, see the Model Streamer documentation.
How does the HF Safetensors Loader work?
The HF Safetensors Loader is an open source utility that provides a safe and fast format for saving and loading multiple tensors. It uses a memory-mapped file system to minimize data copying. On a CPU, tensors are directly mapped into memory. On a GPU, it creates an empty tensor with PyTorch, then moves the tensor data using cudaMemcpy, facilitating a zero-copy loading process.
How does the CoreWeave Tensorizer work?
CoreWeave Tensorizer is an open source tool that serializes model weights and their corresponding tensors into a single file. Instead of loading an entire model into RAM before moving it to the GPU, Tensorizer streams the model data tensor by tensor from an HTTP/HTTPS or S3 source.
Where loading meets inference engines: Loading weights with vLLM
Model serving is not complete without an inference engine. There are many inference engines and servers that one can utilize. This post focuses on vLLM and its model loading capabilities. For the benchmarking study, we only utilized vLLM.
The vLLM framework uses the HF safetensors model loading as default. Additionally, it supports CoreWeave Tensorizer to load models from S3 endpoints. However, note that the Tensorizer library requires converting weights from safetensors format to tensorizer format.
Comparing model loader performance across three storage types
We compared the performance of different model loaders (NVIDIA Run:ai Model Streamer, CoreWeave Tensorizer, and HF Safetensors Loader) across three storage types:
Experiment #1: GP3 SSD – Measured model loading times with various loaders.
Experiment #2: IO2 SSD – Tested the same loaders on IO2 SSD to evaluate the impact of higher IOPS and throughput.
Experiment #3: Amazon S3 – Compared loaders in a cloud storage; Safetensors Loader excluded as it does not support S3.
Experiment #4: vLLM with different loaders – Integrated Model Streamer into vLLM to measure full load and readiness times across storage types, comparing it to default HF Safetensors Loader and Tensorizer. Safetensors Loader excluded from S3 tests.
All tests ran under cold-start conditions to avoid cache effects. For S3, a minimum two-minute wait between tests ensured accuracy. Tensorizer experiments used models serialized per the Tensorizer recipe, and benchmarking followed their benchmarking recipe, both without optional hashing.
Experiment setup
The experiments were conducted using the setup outlined in Table 1.
Model
Llama 3 8B, an LLM weighing 15 GB, stored in a single Safetensors format
Hardware
AWS g5.12xlarge instance featuring four NVIDIA A10G GPUs (only one GPU was used for all tests to maintain consistency)
CUDA 12.4 vLLM 0.5.5 (Transformers 4.44.2) NVIDIA Run:ai Model Streamer 0.6.0 Tensorizer 2.9.0 Transformers 4.45.0.dev0 Accelerate 0.34.2
Storage types
GP3 SSD: 750 GB, 16K IOPS, 1,000 MiB/s IO2 SSD: 500 GB, 100K IOPS, 4,000 MiB/s Amazon S3: Same AWS region as instance to minimize latency
Table 1. Summary of experimental setup
For the experiments involving Tensorizer, the same model was serialized into the Tensorizer proprietary tensor format using the recipe provided by the Tensorizer framework.
Experiment #1 results: GP3 SSD
In this initial experiment, we compared the loading performance of different model loaders using GP3 SSD storage. We evaluated the impact of concurrency on the Model Streamer (Figure 1) and examined how the number of workers affected Tensorizer. For Model Streamer, increasing concurrency—the number of concurrent threads reading from storage into CPU memory—led to a notable decrease in model loading time.
At concurrency 1, Model Streamer loaded the model in 47.56 seconds, slightly slower than HF Safetensors Loader at 47.99 seconds. With concurrency 16, loading time dropped to 14.34 seconds, maintaining throughput of ~1 GiB/s, the max for GP3 SSD. Beyond that, storage throughput limited further gains.
Tensorizer showed similar behavior. With one worker, loading time was 50.74 seconds, close to Safetensors Loader. With 16 workers, it achieved 16.11 seconds and 984.4 MiB/s throughput—also nearing GP3 SSD bandwidth.
The storage throughput limit of GP3 SSD became the bottleneck for both Model Streamer and Tensorizer, limiting performance. This motivated testing a higher-throughput storage solution in Experiment #2.
Model Streamer
Safetensors Loader
Concurrency
Time to load model to GPU (sec.)
Time to load model to GPU (sec.)
1
47.56
47.99
4
14.43
8
14.42
16
14.34
Table 2. Experiment #1 GP3 SSD results
Tensorizer
Number of readers
Time to load model to GPU (sec.)
1
50.74
4
17.38
8
16.49
16
16.11
32
17.18
64
16.44
100
16.81
Table 3. Experiment #1 Tensorizer results
Figure 1. Higher concurrency significantly reduces model loading time, reaching peak SSD throughput at 16 streamsFigure 2. Model Streamer and Tensorizer achieve faster model loading than Safetensors on AWS GP3 SSD
Experiment #2: IO2 SSD
For the second experiment, we used IO2 SSD, which offers significantly higher throughput than GP3 SSD. As before, we analyzed the effect of concurrency on Model Streamer (Figure 3) and the number of workers on Tensorizer.
At concurrency 1, Model Streamer and HF Safetensors Loader showed similar loading times of 43.71 seconds and 47 seconds, respectively. However, as we increased concurrency, Model Streamer showed much more pronounced gains compared to GP3 SSD. With concurrency 8, the model was loaded in just 7.53 seconds, making it around 6x faster than the HF Safetensors Loader, which took 47 seconds.
For Tensorizer, the performance also improved significantly. The optimal result was observed with eight workers, achieving a model loading time of 10.36 seconds (Figure 4). Beyond that, adding more workers did not yield further performance improvements, likely due to storage throughput limitations.
Despite the theoretical maximum throughput of 4 GiB/s for IO2 SSD, our experiments consistently hit a ceiling at around 2 GiB/s with Model Streamer and 1.6 GiB/s with Tensorizer. This suggests practical throughput limitations on the AWS infrastructure, rather than the loaders themselves.
Model Streamer
Safetensors Loader
Concurrency
Time to load model to GPU (sec.)
Time to load model to GPU (sec.)
1
43.71
47
4
11.19
8
7.53
16
7.61
20
7.62
Table 4. Experiment #2 IO2 SSD results
Tensorizer
Number of readers
Time to load model to GPU (sec.)
1
43.85
4
14.44
8
10.36
16
10.61
32
10.95
Table 5. Experiment #2 Tensorizer results
Figure 3. Model loading time with Model Streamer drops sharply as concurrency increases on IO2 SSDFigure 4. Model Streamer and Tensorizer outperform Safetensors Loader on AWS IO2 SSD at optimal concurrency
Experiment #3: S3
For cloud storage, Experiment #3 compared the performance of Model Streamer and Tensorizer using Amazon S3 as the storage medium. Since HF Safetensors Loader does not support S3, it was not included in this benchmarking experiment. For the Tensorizer experiments, we used different numbers of workers and chose the best result for Figure 6, which was achieved with 16 workers in this case.
The results showed that Model Streamer outperformed Tensorizer at all tested concurrency levels. At concurrency 4, Model Streamer loaded the model in 28.24 seconds. As concurrency increased, Model Streamer continued to improve, reaching a load time of 4.88 seconds at concurrency 32, compared to 37.36 seconds for Tensorizer’s best result with 16 workers. This shows that the Model Streamer demonstrates superior efficiency in loading from cloud-based storage.
Note that during these experiments, we observed unexpected caching behavior on AWS S3. When experiments were repeated in quick succession, the model load times significantly improved, likely due to some form of S3 caching mechanism. To ensure consistency and avoid benefiting from this “warm cache,” we introduced at least a 3-minute wait between each test run. The results presented here reflect the times recorded after these intervals, ensuring they represent cold-start conditions.
Model Streamer
Concurrency
Time to load model to GPU (sec.)
4
28.24
16
8.45
32
4.88
64
5.01
Table 6. Experiment #3 S3 results
Tensorizer
Number of readers
Time to load model to GPU (sec.)
8
86.05
16
37.36
32
48.67
64
41.49
80
41.43
Table 7. Experiment #3 Tensorizer results
Figure 5. Model loading time with Model Streamer decreases sharply as concurrency increases on S3 bucket storageFigure 6. Model Streamer outperforms Tensorizer in model loading from AWS S3 at optimal concurrency
Experiment #4: vLLM with all loaders
This experiment integrated different model loaders into vLLM to measure the total time from model loading to readiness for inference. Model Streamer, Safetensors Loader, and Tensorizer were tested on local storage (GP3 SSD and IO2 SSD), while Hugging Face Safetensors was excluded from S3 since it doesn’t support S3 loading. Tensorizer was tested with vLLM on S3 and compared to Model Streamer.
For each vLLM plus Model Streamer experiment, we used the most optimal concurrency levels determined from earlier experiments. Specifically:
For GP3 SSD, a concurrency level of 16 was used (Figure 1).
For IO2 SSD, the concurrency level was also 8 (Figure 3).
For S3 storage, a higher concurrency level of 32 was used (Figure 5).
Similarly, for the Tensorizer plus vLLM integration, we used the most optimal number of workers determined in previous experiments. Specifically:
GP3 SSD: 16 workers
IO2 SSD: 8 workers
S3: 16 workers
Model Streamer reduced total readiness time to 35.08 seconds on GP3 SSD and 28.28 seconds on IO2 SSD, compared to HF Safetensors Loader at 66.13 seconds and 62.69 seconds, respectively. Tensorizer took 36.19 seconds on GP3 and 30.88 seconds on IO2 SSD, similarly cutting times roughly in half versus Safetensors. On S3, Model Streamer achieved 23.18 seconds total readiness, while Tensorizer required 65.18 seconds.
vLLM with different loaders
Loader
Total time until vLLM engine is ready for requests (sec.)
Total time until vLLM engine is ready for requests (sec.)
Model Streamer
23.18
Tensorizer
65.18
Table 10. Experiment #4 vLLM results S3 storage
Figure 7. Model Streamer and Tensorizer reduce total vLLM readiness time across storage types, especially on local SSDs
Get started with NVIDIA Run:ai Model Streamer
Cold start latency remains a key bottleneck in delivering responsive, scalable LLM inference, especially in dynamic or cloud-native environments. Our benchmarks demonstrate that the NVIDIA Run:ai Model Streamer significantly accelerates model loading times across local and remote storage, outperforming other common loaders. By enabling concurrent weight loading and GPU memory streaming, it offers a practical and high-impact solution for production-scale inference workloads.
If you’re building or scaling inference systems, especially with large models or cloud-based storage, these results offer immediate takeaways: use the Model Streamer to reduce cold-start latency, saturate your storage throughput, and accelerate time-to-inference. With easy integration into frameworks like vLLM and support for high-concurrency, multi-storage environments, it’s a drop-in optimization that can yield measurable gains. Boost your model loading performance with the NVIDIA Run:ai Model Streamer.
Jaringan Utara -Selatan: Kunci untuk beban kerja AI perusahaan yang lebih cepat
Dalam infrastruktur AI, data memicu mesin komputasi. Dengan sistem AI agen yang berkembang, di mana beberapa model dan layanan berinteraksi, mengambil konteks eksternal, dan …
Generating text with large language models (LLMs) often involves running into a fundamental bottleneck. GPUs offer massive compute, yet much of that power sits idle because autoregressive generation is inherently sequential: each token requires a full forward pass, reloading weights, and synchronizing memory at every step. This combination of memory access and step-by-step dependency raises latency, underutilizes hardware, and limits system efficiency.
Speculative decoding helps break through this wall. By predicting and verifying multiple tokens simultaneously, this technique shortens the path to results and makes AI inference faster and more responsive, significantly reducing latency while preserving output quality. This post explores how speculative decoding works, when to use it, and how to deploy the advanced EAGLE-3 technique on NVIDIA GPUs.
What is speculative decoding?
Speculative decoding is an inference optimization technique that pairs a target model with a lightweight draft mechanism that quickly proposes several next tokens. The target model verifies those proposals in a single forward pass, accepts the longest prefix that matches its own predictions, and continues from there. Compared with standard autoregressive decoding, which produces one token per pass, this technique lets the system generate multiple tokens at once, cutting latency and boosting throughput without any impact on accuracy.
Though highly capable, LLMs often push the limits of AI hardware, making it challenging to further optimize user experience at scale. Speculative decoding offers an alternative by offloading part of the work to a less resource-intensive model.
Speculative decoding works much like a chief scientist in a laboratory, relying on a less experienced but efficient assistant to handle routine experiments. The assistant rapidly works through the checklist, while the scientist focuses on validation and progress, stepping in to correct or take charge whenever necessary.
With speculative decoding, the lightweight assistant model proposes multiple possible continuations and the larger model verifies them in batches. The ultimate benefit is reducing the number of sequential steps, alleviating memory bandwidth bottlenecks. Critically, this acceleration occurs while preserving output quality, as verification mechanisms will discard any results divergent from what the baseline model itself might generate.
Speculative decoding basics using draft-target and EAGLE-3
This section lays out the core concepts behind speculative decoding, breaking down the mechanics that make it effective. To begin, the transformer forward pass shows how sequences are processed in parallel. Subsequent steps include draft generation, verification, and sampling using a draft-target approach as an example. Together, these fundamentals provide the context needed to understand both the classic draft–target method and advanced techniques like EAGLE-3.
What is the draft-target approach to speculative decoding?
The draft-target approach is the classic implementation of speculative decoding, operating as a two-model system. The primary model is the large, high-quality target model whose output you want to accelerate. Working alongside it is a much smaller, faster draft model, which is often a distilled or simplified version of the target.
Returning to the lab scientist analogy, think of the target as the meticulous scientist ensuring correctness, while the draft is the quick assistant proposing possibilities that the scientist then verifies. Figure 1 shows this partnership in action, with the draft model quickly producing four draft tokens for the target model, which verifies and keeps two while also generating one additional token itself.
Figure 1. The draft-target approach to speculative decoding operates as a two-model system
Speculative decoding using the draft-target approach involves the following steps:
Draft generation
A smaller, more efficient mechanism generates a sequence of candidate tokens (typically 3 to 12 tokens). Typically, this takes the form of a separate smaller model trained on the same data distribution. The target model’s output usually serves as the ground truth for the draft model’s training.
Parallel verification
The target model processes the input sequence and all draft tokens simultaneously in a single forward pass, computing probability distributions for each position. This parallel processing is the key efficiency gain, as it leverages the target model’s full computational capacity rather than leaving it underutilized during sequential generation. Thanks to the KV Cache, where the values for the original prefix have already been calculated and stored, only the new, speculated tokens incur a computational cost during this verification pass. The verified tokens are then selected to form the new prefix for the next generation step.
Rejection sampling
Rejection sampling is the decision-making stage that occurs after the probability distribution from the target model has been generated.
The key aspect of rejection sampling is the acceptance logic. As Figure 2 illustrates, this logic compares the proposed probability of the draft model, P(Draft), against the actual probability of the target model, P(Target).
For the first two tokens, “Brown” and “Fox,” P(Target) is higher than P(Draft), so they are accepted. However, for “Hopped,” P(Target) is significantly lower than P(Draft), indicating an unreliable prediction.
When a token such as “Hopped” is rejected by the acceptance logic, it and all subsequent tokens in the draft are discarded. The process then reverts to standard autoregressive generation from the last accepted token, “Fox,” to produce a corrected token.
Figure 2. The acceptance logic is the key aspect of rejection sampling during parallel verification
Only when a draft token matches what the target model would have generated, is it accepted. This rigorous, token-by-token validation ensures that the final output is identical to what the target model would have produced, guaranteeing that the speedups come with no loss in accuracy.
The number of accepted tokens compared to the total generations is the acceptance rate. Higher acceptance rates equate to more significant speedups and at worst, if all draft tokens are rejected, then only the single target model token is generated.
What is the EAGLE approach to speculative decoding?
EAGLE, or Extrapolation Algorithm for Greater Language-Model Efficiency, is a speculative decoding method that operates at the feature level, extrapolating from the hidden state just before the target model’s output head. Unlike the draft–target approach, which relies on a separate draft model to propose tokens, EAGLE uses a lightweight autoregressive prediction head ingesting features from the target model’s hidden states. This eliminates the overhead of training and running a second model while still allowing the target model to verify multiple token candidates per forward pass.
EAGLE-3, the third version, builds on this foundation by introducing a multi-layer fused feature representations from the target model, taking low, middle, and high-level embeddings directly into its drafting head. It also uses a context-aware, dynamic draft tree (inherited from EAGLE-2) to propose multiple chained hypotheses. These candidate tokens are then verified by the target model using parallel tree attention, effectively pruning invalid branches and improving both acceptance rate and throughput. Figure 3 shows this flow in action.
Figure 3. The EAGLE-3 drafting mechanism generates a tree of candidate tokens from the target model
What is the EAGLE head?
Instead of using a separate, smaller model as in the draft-target approach, EAGLE-3 instead attaches a lightweight drafting component to the internal layers of the target model as an “EAGLE head.” The EAGLE head is typically made of a lightweight Transformer decoder layer followed by a final linear layer. It is essentially a miniature, stripped-down version of the building blocks that make up the main model.
This EAGLE head can generate not just a single sequence, but an entire tree of candidate tokens. This process is also instance-adaptive, where the head evaluates its own confidence as it builds the tree and stops drafting if the confidence drops below a threshold. This allows the EAGLE head to explore multiple generation paths efficiently, generating longer branches of predictable text and shorter ones for complex parts, all for the runtime cost of one forward pass of the target model.
What is Multi-Token-Prediction in DeepSeek-R1?
Similar to EAGLE, Multi-Token Prediction (MTP) is a speculation technique used by many iterations of DeepSeek where the model learns to predict several future tokens at once rather than only the immediate next token. MTP uses a multi-head method where each head acts as a token drafter. The first head attached to the model guesses the first draft token, another guesses the one after that, another the third, and so on. The main model then checks those guesses in order and keeps the longest prefix that matches. This method naturally removes the need for a separate drafting model.
In essence, this technique is similar to EAGLE-style speculative decoding where both propose multiple tokens for verification. However, it differs in how proposals are formed: MTP uses specialized multi-token prediction heads, whereas EAGLE uses a single head that extrapolates internal feature states to construct candidates.
How to implement speculative decoding
You can use the NVIDIA TensorRT-Model Optimizer API to apply speculative decoding to your own models. Follow the steps described below to convert a model to use EAGLE-3 speculative decoding using the Model Optimizer Speculative Decoding module.
Step 1: Load the original Hugging Face model.
import transformers
import modelopt.torch.opt as mto
import modelopt.torch.speculative as mtsp
from modelopt.torch.speculative.config import EAGLE3_DEFAULT_CFG
mto.enable_huggingface_checkpointing()
# Load original HF model
base_model = "meta-llama/Llama-3.2-1B"
model = transformers.AutoModelForCausalLM.from_pretrained(
base_model, torch_dtype="auto", device_map="cuda"
)
Step 2: Import the default config for EAGLE-3 and convert it using mtsp.
# Read Default Config for EAGLE3
config = EAGLE3_DEFAULT_CFG["config"]
# Hidden size and vocab size must match base model
config["eagle_architecture_config"].update(
{
"hidden_size": model.config.hidden_size,
"vocab_size": model.config.vocab_size,
"draft_vocab_size": model.config.vocab_size,
"max_position_embeddings": model.config.max_position_embeddings,
}
)
# Convert Model for eagle speculative decoding
mtsp.convert(model, [("eagle", config)])
Check out the hands-on tutorial that expands this demo into a deployable end-to-end speculative decoding fine‑tuning pipeline in the TensorRT-Model-Optimizer/examples/speculative_decoding GitHub repo.
How does speculative decoding impact inference latency?
The core latency bottleneck in standard autoregressive generation is the fixed, sequential cost of each step. If a single forward pass (loading weights and computing a token) takes 200 milliseconds, generating three tokens will always take 600 ms (three sequential steps multiplied by 200 ms). The user experiences this delay as distinct cumulative waiting periods.
Speculative decoding can collapse these multiple waiting periods into one. By using a fast draft mechanism to speculate two candidate tokens then verifying them all in a single 250 ms forward pass, the model can generate three tokens (two speculations plus one base model generation) in 250 ms versus 600 ms. This concept is illustrated in Figure 4.
Figure 4. Generation with and without speculative decoding
Instead of watching the response appear word by word, the user sees it materialize in much faster, multi-token chunks. This is particularly noticeable in interactive applications like chatbots, where a lower response latency creates a much more fluid and natural conversation. Figure 5 simulates a hypothetical chatbot with speculative decode on and off.
Figure 5. A chatbot with speculative decoding on (right) generates text much faster than with speculative decoding off (left)
Get started with speculative decoding
Speculative decoding is becoming a fundamental strategy for accelerating LLM inference. From the basics of draft–target generation and parallel verification to advanced methods like EAGLE-3, these approaches address the core challenge of idle compute during sequential token generation.
As workloads scale and demand grows for both faster response times and better system efficiency, techniques like speculative decoding will play an increasingly central role. Pairing these methods with frameworks such as NVIDIA TensorRT-LLM, SGLANG, and vLLM ensures that developers can deploy models that are more performant, more practical, and more cost-effective in real-world environments.
Ready to get started? Check out the Jupyter notebook tutorial in the TensorRT-Model-Optimizer/examples/speculative_decoding GitHub repo to try applying speculative decoding to your own model.
Acknowledgments
Thank you to the NVIDIA engineers who contributed to the development and writing of this post, including Chenhan Yu and Hao Guo.
Rilis 25.08 Rapids terus mendorong batas menuju membuat ilmu data yang dipercepat lebih mudah diakses dan diukur dengan penambahan beberapa fitur baru, termasuk:
Dua alat profil baru untuk pemecahan masalah CUML.Accel Code
Dukungan untuk data yang lebih besar dan lebih kompleks di mesin GPU Polar
Dukungan Algoritma Baru di CUML dan CUML.Accel
Pembaruan Dukungan Versi CUDA
Pelajari lebih lanjut tentang fitur baru di bawah ini.
Rilis 25.08 membawa penambahan dua opsi profil baru ke cuml.accel. Mirip dengan profiler yang sebelumnya dirilis untuk cudf.panda, fitur profil baru ini membantu pengguna memahami operasi mana yang dipercepat oleh CUML pada GPU, yang kembali berjalan pada CPU, dan berapa lama operasi ini berlangsung. Ini dapat berguna bagi pengguna yang mencoba memahami kemacetan kinerja saat ini dalam alur kerja pembelajaran mesin mereka.
Pertama, kami memperkenalkan profiler tingkat fungsi. Profiler ini menunjukkan kepada pengguna semua operasi dalam skrip atau sel tertentu yang dijalankan pada GPU vs CPU. Ini juga menunjukkan jumlah waktu yang diambil masing -masing fungsi pada masing -masing.
Ada dua cara untuk menggunakan profiler tingkat fungsi. Jika menjalankan notebook Jupyter atau Ipython, pengguna dapat menelepon %%cuml.accel.profile setelah cuml.accel telah dimuat dan profil seluruh sel:
%%cuml.accel.profile
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100)
# Fit and predict on GPU
ridge = Ridge(alpha=1.0)
ridge.fit(X, y)
ridge.predict(X)
# Retry, using an unsupported hyperparameter
ridge = Ridge(positive=True)
ridge.fit(X, y)
ridge.predict(X)
Output sel ini berisi hasil profil:
cuml.accel profile
┏━━━━━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━┓
┃ Function ┃ GPU calls ┃ GPU time ┃ CPU calls ┃ CPU time ┃
┡━━━━━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━┩
│ Ridge.fit │ 1 │ 141.2ms │ 1 │ 3ms │
│ Ridge.predict │ 1 │ 31.5ms │ 1 │ 97.3µs │
├───────────────┼───────────┼──────────┼───────────┼──────────┤
│ Total │ 2 │ 172.7ms │ 2 │ 3.1ms │
└───────────────┴───────────┴──────────┴───────────┴──────────┘
Not all operations ran on the GPU. The following functions required CPU fallback for the following reasons:
* Ridge.fit
- `positive=True` is not supported
* Ridge.predict
- Estimator not fit on GPU
Profiler tingkat fungsi juga dapat dipanggil pada skrip Python menggunakan --profile Bendera dari CLI:
python -m cuml.accel --profile script.py
Profiler kedua adalah profiler tingkat garis, menunjukkan kepada pengguna di mana setiap bagian kode dieksekusi garis demi garis. Seperti profiler tingkat fungsi, profiler tingkat garis dapat dipanggil dalam buku catatan dengan %%cuml.accel.line_profile.
%%cuml.accel.line_profile
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100)
# Fit and predict on GPU
ridge = Ridge(alpha=1.0)
ridge.fit(X, y)
ridge.predict(X)
# Retry, using an unsupported hyperparameter
ridge = Ridge(positive=True)
ridge.fit(X, y)
ridge.predict(X)
Profiler garis juga dapat dipanggil melalui --line-profile Bendera dari baris perintah:
python -m cuml.accel --line-profile script.py
Dengan kemampuan profil baru ini, cuml.accel Memberikan lebih banyak alat untuk membuat kode pembelajaran mesin yang mempercepat dan men -debugging lebih mudah.
Proses data yang lebih besar dan lebih kompleks dengan mesin GPU POLAR yang ditenagai oleh NVIDIA CUDF
Bekerja dengan set data yang lebih besar dari memori GPU dengan pelaksana streaming default baru
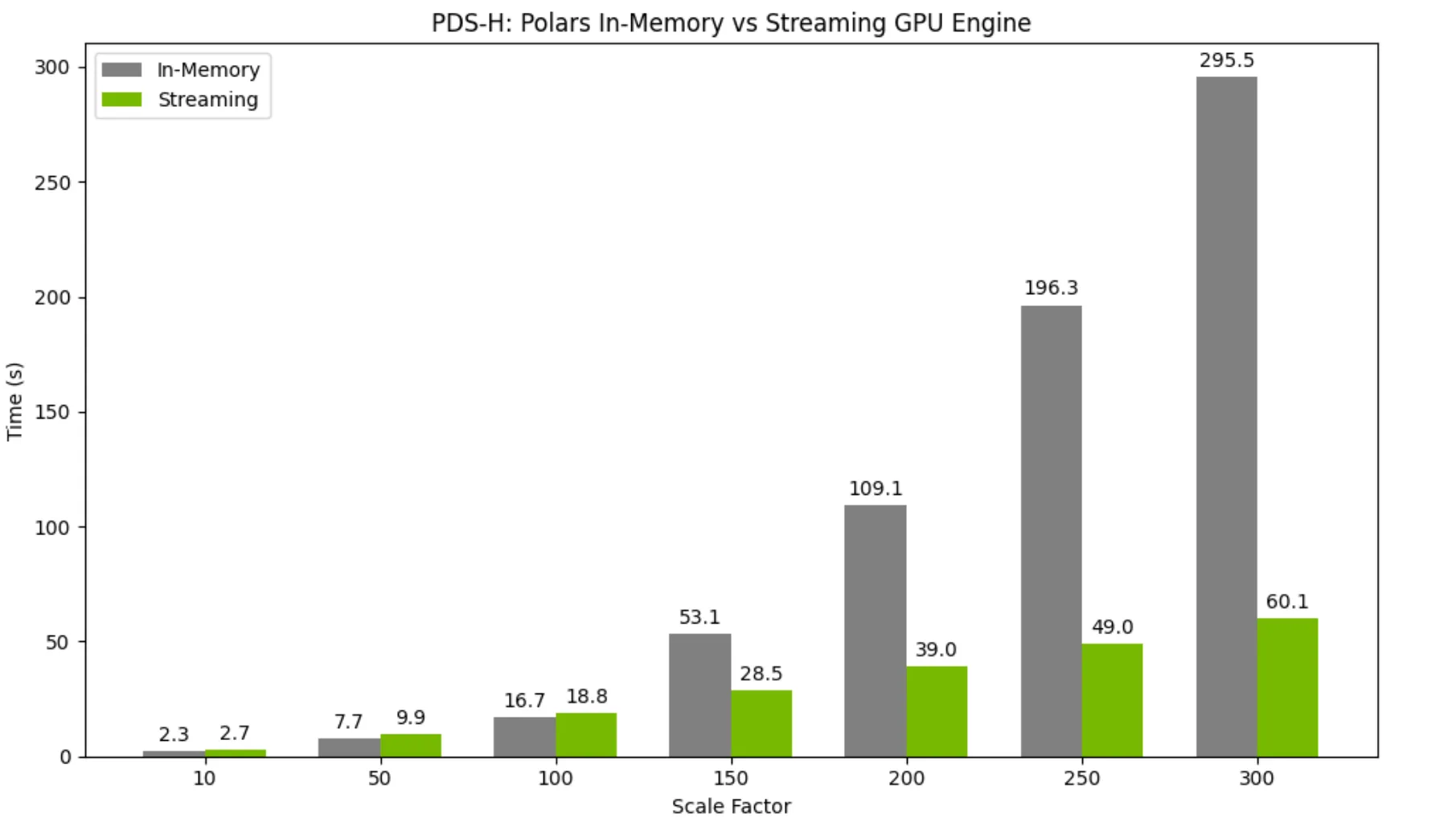
Mode eksekusi streaming yang diperkenalkan sebagai fitur eksperimental di 25.06 sekarang merupakan default di mesin GPU POLAR. Eksekutor baru ini mengambil keuntungan dari partisi data untuk memungkinkan dataset yang jauh lebih besar dari VRAM (memori GPU) diproses secara efisien. Pelaksana streaming masih dapat kembali ke eksekusi dalam memori untuk setiap operasi yang tidak didukung, tetapi pada rilis 25.08, eksekusi streaming mendukung hampir semua operator yang didukung untuk eksekusi GPU dalam memori. Ini membuka kinerja substansial dan peningkatan skalabilitas.
Untuk set data yang lebih kecil, menggunakan mode eksekusi streaming pada GPU tunggal menimbulkan overhead kinerja yang sangat kecil jika dibandingkan dengan menggunakan mesin dalam memori. Namun, ketika ukuran dataset tumbuh dan mulai melebihi memori GPU, pelaksana streaming memberikan percepatan besar dibandingkan dengan mesin dalam memori.
Gambar 1. Perbandingan kinerja mode eksekusi mesin dan streaming mesin GPU POLAR. Mesin streaming hampir 5x lebih cepat pada beban kerja 300GB lebih besar dari memori.
Untuk informasi lebih lanjut tentang pelaksana streaming GPU Polar, kunjungi dokumentasi kami.
Simpan data kompleks seperti struct dan operasi string di GPU
Mesin GPU Polar sekarang mendukung data struct di kolom. Sebelumnya, setiap operasi yang melibatkan struct akan kembali ke eksekusi CPU, tetapi dengan rilis terbaru semua operasi ini sekarang diperkuat GPU untuk peningkatan kinerja:
Selain itu, mesin GPU POLAR sekarang mendukung serangkaian operator string yang diperluas secara substansial, misalnya:
>>> ldf = pl.LazyFrame({"foo": [1, None, 2]})
>>> ldf.select(pl.col("foo").str.join("-")).collect(engine=gpu_engine)
shape: (1, 1)
┌─────┐
│ foo │
│ --- │
│ str │
╞═════╡
│ 1-2 │
└─────┘
>>> ldf = pl.LazyFrame({
... "lines": [
... "I Like\nThose\nOdds",
... "This is\nThe Way",
... ]
... })
... ldf.with_columns(
... pl.col("lines").str.extract(r"(T\w+)", 1).alias("matches"),
... ).collect(engine=pl.GPUEngine(raise_on_fail=True))
...
shape: (2, 2)
┌─────────┬──────┐
│ lines ┆ matches │
│ --- ┆ --- │
│ str ┆ str │
╞═════════╪══════╡
│ I Like ┆ Those │
│ Those ┆ │
│ Odds ┆ │
│ This is ┆ This │
│ The Way ┆ │
└─────────┴──────┘
Perluasan dukungan tipe data semakin memperkuat kemampuan mesin GPU POLAR, mempercepat pengiriman fungsionalitas pengguna akhir yang paling umum.
Algoritma baru didukung dalam cuml: embedding spektral, linearsvc, linearsvr, dan kernelridge
Dengan rilis 25.08, CUML telah menambahkan algoritma embedding spektral untuk pengurangan dimensi dan pembelajaran berlipat ganda. Embedding spektral adalah pendekatan yang menggunakan nilai eigen dan vektor eigen dari grafik kesamaan untuk menanamkan data dimensi tinggi ke dalam ruang dimensi yang lebih rendah.
API untuk algoritma embedding spektral baru dalam CUML cocok dengan implementasi embedding spektral di scikit-learn:
from cuml.manifold import SpectralEmbedding
import cupy as cp
from sklearn.datasets import fetch_openml
# (70000, 784) -> (70000, 2)
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist.data, mnist.target.astype(int)
spectral = SpectralEmbedding(n_components=2, n_neighbors=None, random_state=42)
embedding = spectral.fit_transform(cp.asarray(X, order='C', dtype=cp.float32))
Selain itu, CUML.Accel sekarang mempercepat beberapa algoritma baru dengan perubahan kode nol. LinearSVC dan LinearSVR Estimator ditambahkan dalam rilis 25.08, yang berarti bahwa semua estimator dalam keluarga mesin vektor dukungan sekarang menjadi bagian dari CUML.Accel.
Kernelridge juga ditambahkan ke CUML.Accel, membawa algoritma regresi populer lainnya di bawah payung perubahan kode nol.
Untuk informasi lebih lanjut tentang algoritma yang didukung hari ini, lihat dokumentasi lengkap kami.
Dukungan Dukungan Cuda 11
Dimulai dengan rilis 25.08, kami menjatuhkan dukungan untuk CUDA 11, yang mencakup semua kontainer, paket yang diterbitkan, dan kemampuan untuk membangun dari sumber. Pengguna yang ingin terus menjalankan CUDA 11 Mei Pin ke Rapids versi 25.06.
Kunjungi dokumentasi Rapids untuk mempelajari lebih lanjut.
Kesimpulan
Rilis Nvidia Rapids 25.08 menawarkan lompatan ke depan dalam mempercepat dan mengoptimalkan alur kerja ilmu data. Dengan diperkenalkannya CUML.Accel Profiler, pengembang sekarang memiliki alat yang kuat untuk mendiagnosis dan meningkatkan kinerja kode pembelajaran mesin mereka. Pembaruan untuk mesin GPU POLAR seperti pelaksana streaming dan dukungan tipe data yang diperluas memungkinkan pemrosesan yang efisien dari set data yang besar, meningkatkan skalabilitas dan kinerja. Selain itu, dimasukkannya algoritma baru dalam CUML lebih lanjut merampingkan ekosistem pembelajaran mesin. Perkembangan ini secara kolektif berkontribusi untuk membuat ilmu data yang dipercepat lebih mudah diakses dan efisien bagi pengguna. Untuk menyelam lebih dalam ke semua fitur dan peningkatan baru, pastikan untuk mengunjungi dokumentasi Rapids.
Kami menyambut umpan balik Anda di GitHub. Anda juga dapat bergabung dengan 3.500 anggota komunitas Rapids Slack untuk berbicara pemrosesan data yang dipercepat GPU.
Jika Anda baru mengenal Rapids, periksa sumber daya ini untuk memulai dan mengambil alur kerja Ilmu Data Akselerasi kami dengan Nol Kode Perubahan Kursus secara gratis. Untuk mempelajari lebih lanjut tentang ilmu data yang dipercepat, jelajahi jalur pembelajaran DLI kami dan mendaftar dalam kursus langsung, seperti praktik terbaik dalam rekayasa fitur untuk data tabel dengan akselerasi GPU.
Buat umpan RSS Anda berfungsi lebih baik dengan berintegrasi dengan platform favorit Anda. Hemat waktu dengan menghubungkan alat Anda bersama. Tidak diperlukan pengkodean
Tambahkan umpan berita dinamis ke situs web Anda menggunakan widget kami yang dapat disesuaikan. Tidak diperlukan pengkodean!