[ad_1]
Model bahasa besar (LLM) berada di garis depan inovasi AI, tetapi ukurannya yang besar dapat memperumit efisiensi inferensi. Model seperti LLAMA 3 70B dan LLAMA 4 Scout 109b mungkin memerlukan lebih banyak memori daripada yang termasuk dalam GPU, terutama ketika memasukkan jendela konteks yang besar.
Misalnya, memuat model Llama 3 70b dan Llama 4 Scout 109B dalam presisi setengah (FP16) masing -masing masing -masing membutuhkan sekitar 140 GB dan 218 GB memori. Selama inferensi, model-model ini biasanya memerlukan struktur data tambahan seperti cache nilai kunci (kV), yang tumbuh dengan panjang konteks dan ukuran batch. Cache KV yang mewakili jendela konteks token 128K untuk satu pengguna (ukuran batch 1) mengkonsumsi sekitar 40 GB memori dengan Llama 3 70B, dan ini berskala secara linear dengan jumlah pengguna. Dalam penyebaran produksi, mencoba memuat model besar sepenuhnya ke dalam memori GPU dapat menghasilkan kesalahan out-of-memory (OOM).
CPU dan GPU di NVIDIA Grace Blackwell dan Nvidia Grace Hopper Architectures terhubung dengan nvidia nvlink C2C, 900 gb/s, interkoneksi memori-koheren yang memberikan pidato pcu pcu dari pcu. Untuk mengakses dan beroperasi pada data yang sama tanpa transfer data eksplisit atau salinan memori yang berlebihan.
Pengaturan ini memungkinkan kumpulan data dan model yang besar untuk diakses dan diproses lebih mudah, bahkan ketika ukurannya melebihi batas memori GPU tradisional. Koneksi bandwidth tinggi dari koneksi NVLink-C2C dan arsitektur memori terpadu yang ditemukan dalam Grace Hopper dan Grace Blackwell meningkatkan efisiensi penyempurnaan LLM, kV cache yang tidak ada, inferensi, komputasi ilmiah, dan banyak lagi, memungkinkan model untuk memindahkan data dengan cepat dan menggunakan memori CPU jika tidak ada cukup memori GPU.
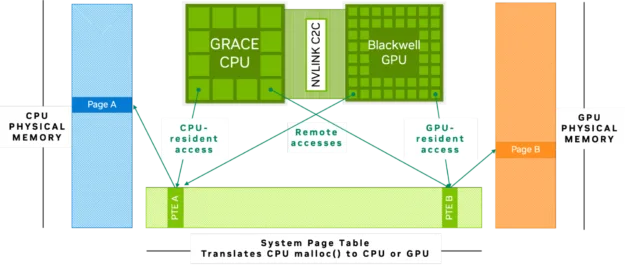
Misalnya, ketika model dimuat ke platform seperti NVIDIA GH200 Grace Hopper Superchip, yang menampilkan arsitektur memori terpadu, ia menggunakan 96 GB memori GPU bandwidth tinggi dan mengakses memori LPDDR 480 GB yang terhubung ke CPU tanpa perlu transfer data eksplisit. Ini memperluas total memori yang tersedia, membuatnya layak untuk bekerja dengan model dan kumpulan data yang seharusnya terlalu besar untuk GPU saja.
Panduan Kode
Dalam posting blog ini, menggunakan model LLAMA 3 70B dan Superchip GH200 sebagai contoh kami, kami akan menunjukkan bagaimana model besar dapat dialirkan ke GPU menggunakan memori terpadu, menggambarkan konsep yang dibahas di atas.
Memulai
Untuk memulai, kita perlu mengatur lingkungan kita dan mendapatkan akses ke model LLAMA 3 70B. Perhatikan bahwa sampel kode berikut dirancang untuk dijalankan pada mesin superchip NVIDIA Grace Hopper GH200 untuk menunjukkan manfaat dari arsitektur memori terpadu. Teknik-teknik yang sama ini juga bekerja pada sistem yang berbasis di NVIDIA Grace Blackwell.
Ini melibatkan beberapa langkah sederhana:
- Minta akses model dari wajah pelukan: Kunjungi halaman model LLAMA 3 70B tentang memeluk wajah untuk meminta akses.
- Menghasilkan token akses: Setelah permintaan Anda disetujui, buat token akses di pengaturan akun pemeluk Anda. Token ini akan digunakan untuk mengotentikasi akses Anda ke model secara terprogram.
- Instal Paket yang Diperlukan: Sebelum Anda dapat berinteraksi dengan model, instal perpustakaan Python yang diperlukan. Buka Jupyter Notebook di mesin GH200 dan jalankan perintah berikut:
#Install huggingface and cuda packages
!pip install --upgrade huggingface_hub
!pip install transformers
!pip install nvidia-cuda-runtime-cu12
- Masuk ke Wajah Memeluk: Setelah memasang paket, masuk ke wajah memeluk menggunakan token yang Anda hasilkan. Perpustakaan HuggingFace_Hub menyediakan cara yang nyaman untuk melakukan ini:
#Login into huggingface using the generated token
from huggingface_hub import login
login("enter your token")Apa yang terjadi ketika model LLAMA 3 70B dimuat ke GH200?
Ketika Anda mencoba memuat model LLAMA 3 70B ke dalam memori GPU, parameternya (bobot) dimuat ke memori GPU (memori NVIDIA CUDA). Dalam setengah presisi (FP16), bobot ini membutuhkan sekitar 140 GB memori GPU. Karena GH200 hanya menyediakan 96 GB memori, model tidak dapat sepenuhnya sesuai dengan memori yang tersedia, dan proses pemuatan akan gagal dengan kesalahan OOM. Di sel berikutnya, kami akan menunjukkan perilaku ini dengan contoh kode.
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="meta-llama/Llama-3.1-70B") #loads the model into the GPU memorySaat menjalankan perintah di atas, kami melihat pesan kesalahan berikut:
Error message:
OutOfMemoryError: CUDA out of memory. Tried to allocate 896.00 MiB. GPU 0 has a total capacity of 95.00 GiB of which 524.06 MiB is free. Including non-PyTorch memory, this process has 86.45 GiB memory in use. Of the allocated memory 85.92 GiB is allocated by PyTorch, and 448.00 KiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management.Dari pesan kesalahan, kita dapat melihat bahwa memori GPU maksimal. Anda juga dapat mengonfirmasi status memori GPU Anda dengan menjalankan:
!nvidia-smiSaat menjalankan perintah, Anda harus mendapatkan output yang mirip dengan gambar berikut. Output memberi tahu kami bahwa kami telah mengkonsumsi 96,746 GB memori dari 97,871 GB pada GPU. Lihat forum ini untuk lebih memahami cara menafsirkan output.
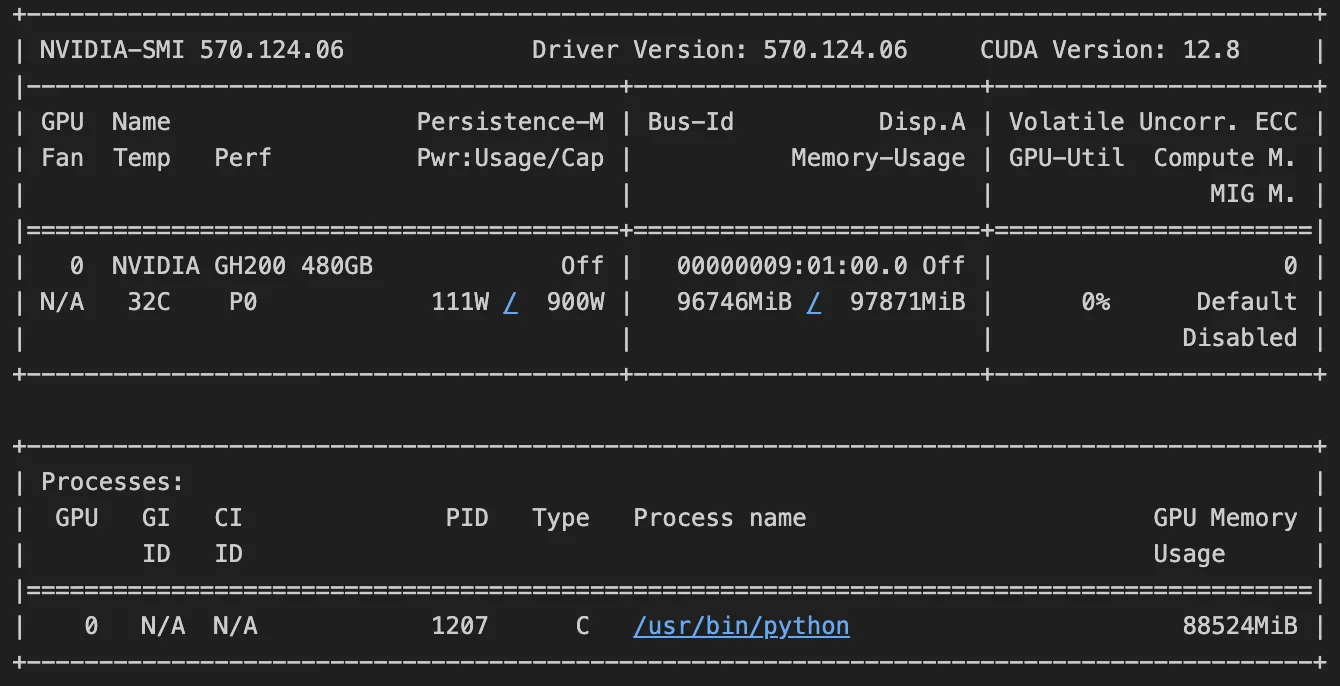
Untuk mempersiapkan langkah -langkah kami berikutnya dan melepaskan memori GPU, kami akan menghapus variabel yang tersisa dari upaya yang gagal ini. Di perintah di bawah ini, ganti
!kill -9 <PID>Bagaimana cara menyelesaikan kesalahan OOM ini?
Masalah ini dapat diselesaikan dengan menggunakan alokasi memori yang dikelola, yang memungkinkan GPU untuk mengakses memori CPU selain memorinya sendiri. Pada sistem GH200, arsitektur memori terpadu memungkinkan CPU (hingga 480 GB) dan GPU (hingga 144 GB) untuk berbagi ruang alamat tunggal dan mengakses memori masing -masing secara transparan secara transparan. Mengkonfigurasi pustaka Rapids Memory Manager (RMM) untuk menggunakan memori yang dikelola, pengembang dapat mengalokasikan memori yang dapat diakses dari GPU dan CPU, memungkinkan beban kerja untuk melebihi batas memori GPU fisik tanpa transfer data manual.
import rmm
import torch
from rmm.allocators.torch import rmm_torch_allocator
from transformers import pipeline
rmm.reinitialize(managed_memory=True) #enabling access to CPU memory
torch.cuda.memory.change_current_allocator(rmm_torch_allocator)
#instructs PyTorch to use RMM memory manager to use unified memory for all memory allocations
pipe = pipeline("text-generation", model="meta-llama/Llama-3.1-70B")Menjalankan perintah pemuatan model, kami tidak menghadapi kesalahan memori OOO, karena sekarang kami memiliki akses ke ruang memori yang lebih besar.
Anda sekarang dapat menggunakan perintah untuk mengirim prompt ke LLM dan menerima tanggapan.
pipe("Which is the tallest mountain in the world?")Kesimpulan
Karena ukuran model terus tumbuh, memuat parameter model ke GPU telah menjadi tantangan yang signifikan. Di blog ini, kami mengeksplorasi bagaimana arsitektur memori terpadu membantu mengatasi keterbatasan ini dengan memungkinkan akses ke CPU dan memori GPU tanpa perlu transfer data yang eksplisit, membuatnya lebih mudah untuk bekerja dengan LLMS canggih pada perangkat keras modern.
Untuk mempelajari lebih lanjut tentang cara mengelola memori CPU dan GPU, lihat dokumentasi Rapid Memory Manager.
[ad_2]
Akselerasi Inferensi LLM Skala Besar dan KV Cache Diperoleh dengan Berbagi Memori CPU-GPU