[ad_1]
Ketika model AI tumbuh lebih besar dan memproses urutan teks yang lebih lama, efisiensi menjadi sama pentingnya dengan skala.
Untuk menampilkan apa yang berikutnya, Alibaba merilis dua model terbuka baru, QWEN3-Next 80B-A3B-Thinking dan QWEN3-Next 80B-A3B-instruct untuk mempratinjau campuran hybrid baru arsitektur para ahli (MOE) dengan riset dan komunitas pengembang.
Qwen3-next-80b-a3b-Thinking sekarang hidup di build.nvidia.com, memberikan pengembang akses instan untuk menguji kemampuan penalaran canggihnya secara langsung di UI atau melalui NVIDIA NIM API.
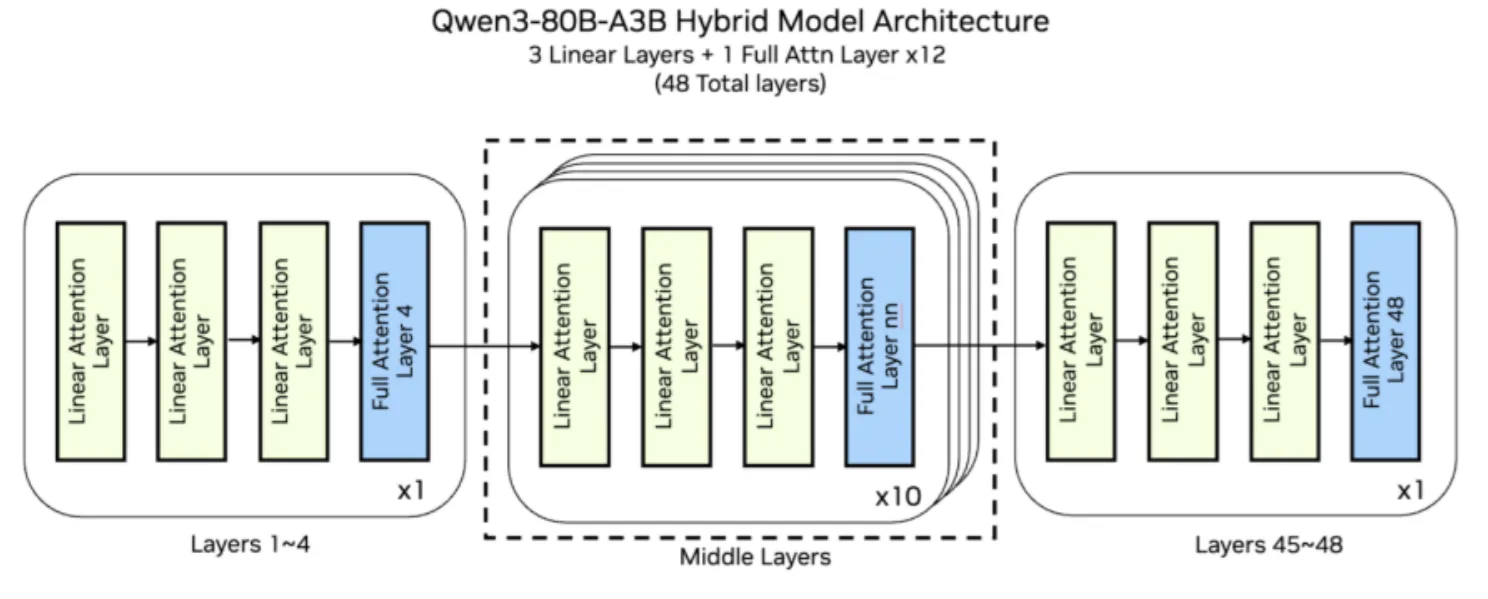
Arsitektur baru dari model QWEN3-Next ini dioptimalkan untuk panjang konteks yang panjang (> 260K token input) dan efisiensi parameter skala besar. Setiap model memiliki total parameter 80B, tetapi hanya 3B yang diaktifkan per token karena struktur MOE yang jarang, memberikan kekuatan model besar dengan efisiensi yang lebih kecil. Modul MOE memiliki 512 pakar yang dirutekan dan 1 ahli bersama, dengan 10 ahli diaktifkan per token.
Kinerja model MOE seperti QWEN3-Next, yang rute meminta antara 512 ahli yang berbeda, sangat tergantung pada komunikasi antar-GPU. NVLink generasi ke-5 Blackwell menyediakan 1,8 TB/s bandwidth GPU-ke-GPU langsung. Kain berkecepatan tinggi ini sangat penting untuk meminimalkan latensi selama proses perutean ahli, secara langsung diterjemahkan ke inferensi yang lebih cepat dan throughput token yang lebih tinggi di pabrik AI.
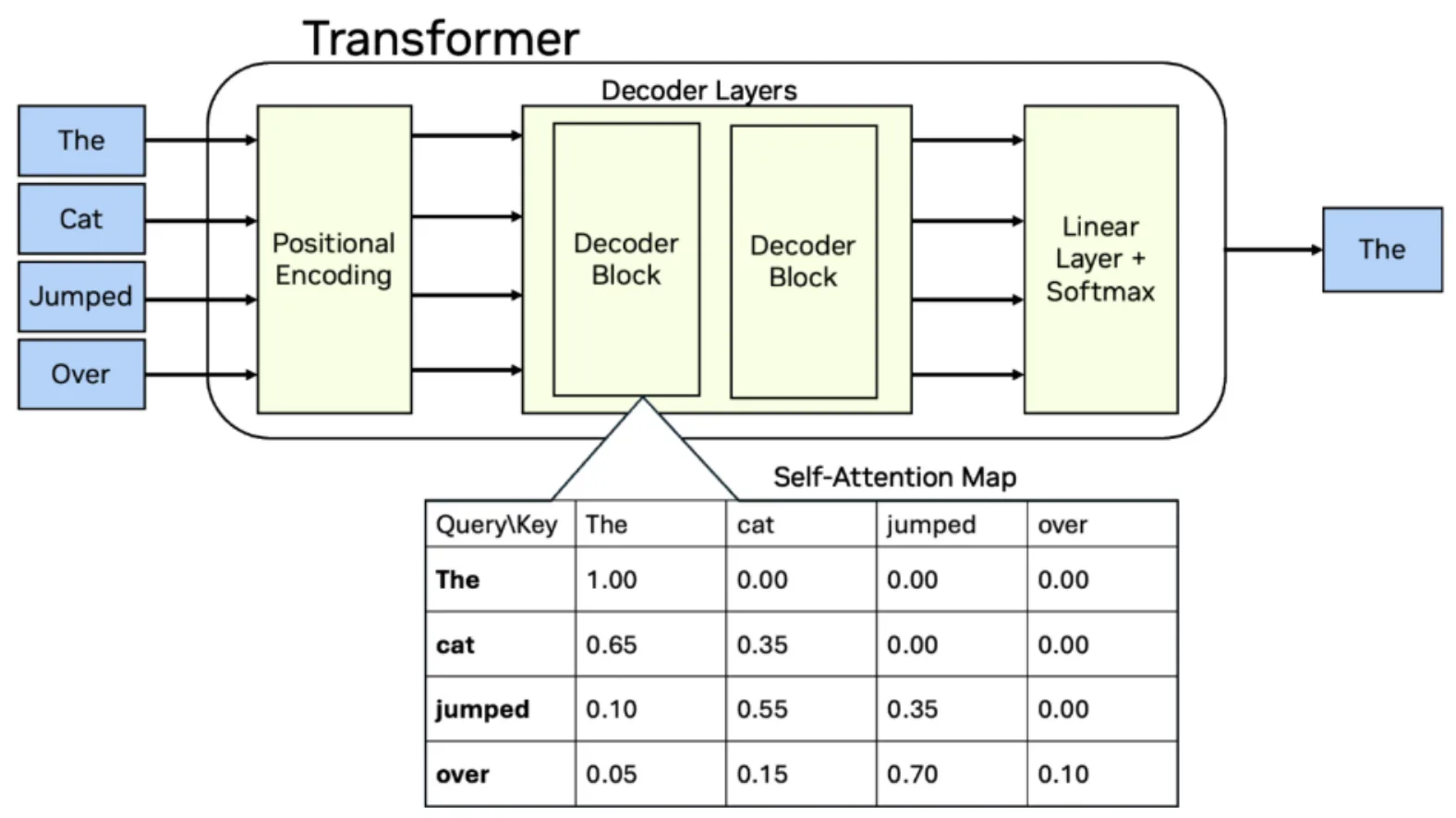
Ada 48 lapisan dalam model, setiap lapisan ke -4 menggunakan perhatian GQA sementara yang tersisa menggunakan perhatian linier baru. Model Bahasa Besar (LLM) menggunakan lapisan perhatian untuk menafsirkan dan memberikan kepentingan untuk setiap token dari urutan input. Tumpukan perangkat lunak yang kurang matang tidak memiliki primitif yang dioptimalkan sebelumnya untuk arsitektur baru atau fusi spesifik yang diperlukan untuk membuat pergantian konstan antara jenis perhatian menjadi efisien.
Untuk mencapai kemampuan konteks input yang panjang, model ini memanfaatkan jaringan delta yang terjaga keamanannya dari NVIDIA Research and MIT. Deltanet yang terjaga keamanannya meningkatkan pemrosesan urutan fokus sehingga model dapat memproses teks super panjang secara efisien tanpa melayang atau melupakan apa yang penting. Ini memungkinkannya untuk memproses urutan yang sangat panjang secara efisien, dengan memori dan penskalaan perhitungan hampir secara linier dengan panjang urutan.
Selain inovasi arsitektur ini, model ini dapat dijalankan di Nvidia Hopper dan Blackwell untuk kinerja inferensi yang dioptimalkan. Arsitektur pemrograman CUDA yang fleksibel dari NVIDIA memungkinkan untuk eksperimen pendekatan baru dan unik, memungkinkan lapisan perhatian penuh dari model transformator tradisional dan lapisan perhatian linier dalam model QWEN3-Next. Ketika dijalankan pada NVIDIA, pendekatan hibrida yang terlihat pada model QWEN3-Next dapat menyebabkan keuntungan efisiensi, membuka jalan bagi generasi token yang lebih besar dan pendapatan untuk pabrik AI.
NVIDIA berkolaborasi dengan kerangka open source SGLANG dan VLLM untuk memungkinkan penyebaran model bagi masyarakat serta mengemas kedua model sebagai NVIDIA NIM. Pengembang dapat mengkonsumsi model terbuka terkemuka melalui wadah perangkat lunak perusahaan, tergantung pada kebutuhan mereka.
Menyebarkan dengan sgang
Pengguna yang menggunakan model dengan kerangka kerja melayani SGLang dapat menggunakan instruksi berikut. Lihat dokumentasi SGLang untuk informasi lebih lanjut dan opsi konfigurasi.
python3 -m sglang.launch_server --model Qwen/Qwen3-Next-80B-A3B-Instruct --tp 4
Menyebarkan dengan VLLM
Pengguna yang menggunakan model dengan kerangka kerja VLLM dapat menggunakan instruksi berikut. Lihat blog pengumuman VLLM untuk informasi lebih lanjut.
uv pip install vllm --extra-index-url https://wheels.vllm.ai/nightly --torch-backend=auto
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct -tp 4
Penempatan siap-produksi dengan NVIDIA NIM
Pengembang perusahaan dapat mencoba QWEN3-Next-80B-A3B bersama dengan sisa model QWEN secara gratis menggunakan titik akhir NIM Microservice yang di-host NVIDIA dalam katalog NVIDIA API. Layanan mikro NIM yang dikemas dan dioptimalkan untuk model juga akan segera diunduh.
Membangun Kekuatan Open Source AI
Arsitektur hybrid moe qwen3-next baru mendorong batas efisiensi dan penalaran, menandai kemajuan yang signifikan bagi masyarakat. Membuat model -model ini tersedia secara terbuka memberdayakan para peneliti dan pengembang di mana -mana untuk bereksperimen, membangun, dan mempercepat inovasi. Di NVIDIA, kami berbagi komitmen ini untuk open source melalui kontribusi seperti NEMO untuk manajemen siklus hidup AI, Nemotron LLMS, dan Cosmos World Foundation Models (WFMS). Kami bekerja bersama komunitas untuk memajukan keadaan AI. Bersama -sama, upaya ini memastikan bahwa masa depan model AI tidak hanya lebih kuat, tetapi lebih mudah diakses, transparan, dan kolaboratif.
Mulailah hari ini
Coba model pada router terbuka: qwen3-next-80b-a3b-thinking dan qwen3-next-80b-a3b-instruct atau unduh dari pemeluk wajah: qwen3-next-80b-a3b-thinking dan qwen3-nex-80b-a3b-instruct