Musim dingin akan datang! Brr, rasakan itu? Ya, bagi banyak dari kita, musim dingin pertama sudah tiba, yang berarti lebih banyak waktu di dalam ruangan. Oleh karena itu, COGconnected telah menjelajahi internet untuk mencari penawaran menarik guna membuat transisi dalam ruangan Anda lebih menyenangkan. Berikut adalah berbagai macam penawaran umum untuk mouse, keyboard, monitor, dan beberapa penawaran menarik. Khusus untuk headphone. Lihat penawaran di bawah ini karena, COGconnected siap membantu Anda.
Semoga daftar ini membantu Anda. Pastikan untuk memeriksa lagi pada akhir pekan depan karena kami memberikan penawaran perangkat keras terbaru kepada Anda!
Sedang berpikir untuk terjun ke AppLovin, atau tidak yakin apakah peningkatan besar berarti Anda ketinggalan? Mari kita lihat lebih dekat apakah Anda harus bersemangat, berhati-hati, atau keduanya.
Sahamnya telah meroket lebih tinggi tahun ini, naik secara mengejutkan sebesar 81,4% year to date dan 113,8% yang luar biasa selama 12 bulan terakhir. Namun, penurunannya sedikit terjadi dalam seminggu dan bulan terakhir.
Investor sangat tertarik baru-baru ini karena AppLovin menjadi berita utama atas langkah beraninya di bidang teknologi periklanan, termasuk peluncuran alat baru yang digerakkan oleh AI dan kemitraan utama dengan pengembang aplikasi besar. Hal ini memicu optimisme mengenai pertumbuhan di masa depan dan posisi kompetitif.
Terlepas dari semua kegembiraan tersebut, AppLovin mendapat skor 0 dari 6 pada daftar penilaian kami, menunjukkan bahwa ada banyak hal yang perlu dibongkar dalam hal harga versus nilai. Kami akan merinci apa yang dikatakan oleh semua metrik penilaian standar selanjutnya, tetapi tetap mencari cara yang lebih cerdas untuk memikirkan tentang nilai AppLovin yang sebenarnya.
AppLovin hanya mendapat skor 0/6 pada pemeriksaan penilaian kami. Lihat tanda bahaya lain yang kami temukan dalam rincian penilaian lengkap.
Pendekatan 1: Analisis Arus Kas Diskon (DCF) AppLovin
Model Discounted Cash Flow (DCF) adalah metode penilaian yang banyak digunakan untuk memperkirakan nilai sebenarnya suatu bisnis dengan memproyeksikan arus kas masa depan dan mendiskontokannya kembali ke dolar saat ini. Pendekatan ini membantu investor menilai nilai perusahaan hanya berdasarkan berapa banyak uang tunai yang diharapkan dapat dihasilkan di masa depan.
Bagi AppLovin, dua belas bulan terakhir menghasilkan Arus Kas Bebas (FCF) sebesar $3,4 Miliar. Analis memproyeksikan FCF akan tumbuh secara substansial, mencapai $8,8 Miliar pada tahun 2029. Setelah lima tahun, perkiraan ini bergantung pada ekstrapolasi daripada perkiraan analis langsung, namun jalur pertumbuhan yang cepat terlihat jelas dari masukan yang diberikan oleh Simply Wall St dan analis pasar.
Setelah arus kas masa depan didiskontokan kembali ke nilai sekarang menggunakan model Arus Kas Bebas ke Ekuitas 2 Tahap, perkiraan nilai intrinsik AppLovin menjadi $541,93 per saham. Namun, dengan harga saham saat ini yang diperdagangkan pada premi 14,4% dari nilai intrinsik tersebut, model tersebut menunjukkan bahwa saham tersebut dinilai terlalu tinggi saat ini.
Hasil: DIHARGAI TERLEBIH DAHULU
Analisis Arus Kas Diskon (DCF) kami menunjukkan bahwa AppLovin mungkin dinilai terlalu tinggi sebesar 14,4%. Temukan 876 saham yang dinilai terlalu rendah atau buat penyaring Anda sendiri untuk menemukan peluang nilai yang lebih baik.
Arus Kas Diskon APP per November 2025
Kunjungi bagian Penilaian di Laporan Perusahaan kami untuk detail lebih lanjut tentang cara kami mencapai Nilai Wajar untuk AppLovin ini.
Pendekatan 2: Harga AppLovin vs Pendapatan
Rasio Price-to-Earnings (PE) adalah metode penilaian inti bagi perusahaan-perusahaan yang menguntungkan seperti AppLovin karena menghubungkan harga saham secara langsung dengan pendapatan perusahaan. Hal ini membuat PE sangat berguna ketika bisnis menghasilkan keuntungan yang konsisten, memberikan investor metrik yang jelas dan dapat dibandingkan mengenai jumlah yang bersedia dibayar pasar untuk setiap dolar keuntungan.
Namun, rasio PE yang ideal atau “adil” bukanlah angka yang bisa digunakan untuk semua. Nilai ini cenderung naik pada perusahaan-perusahaan yang tumbuh cepat atau berisiko rendah, karena investor bersedia membayar mahal untuk prospek atau stabilitas yang kuat. Demikian pula, perusahaan dengan pertumbuhan yang lebih lambat atau risiko yang lebih tinggi biasanya melakukan perdagangan dengan PE yang lebih rendah dibandingkan dengan pasar atau sektor yang lebih luas.
AppLovin saat ini diperdagangkan pada rasio PE sebesar 71,9x, yang lebih tinggi dibandingkan rata-rata perusahaan sejenis sebesar 46,0x dan rata-rata industri Perangkat Lunak yang lebih luas sebesar 34,3x. Hal ini menunjukkan investor menaruh ekspektasi yang sangat optimis terhadap pertumbuhan di masa depan.
Daripada berhenti pada perbandingan rekan atau industri, Simply Wall St menghitung “Rasio Wajar” yang memperhitungkan pertumbuhan pendapatan AppLovin, margin keuntungan, konteks industri, ukuran perusahaan, dan profil risiko. Bagi AppLovin, Rasio Wajar adalah 58,5x, dirancang untuk mencerminkan ekspektasi yang lebih disesuaikan dan holistik mengenai jumlah yang harus dibayar investor secara wajar saat ini untuk pendapatan perusahaan.
Membandingkan rasio PE aktual AppLovin sebesar 71,9x dengan Rasio Wajar sebesar 58,5x menunjukkan bahwa saham tersebut diperdagangkan jauh di atas apa yang dapat dibenarkan oleh kondisi fundamental dan spesifiknya, bahkan ketika memperhitungkan pertumbuhan dan keunggulan industrinya.
Hasil: DIHARGAI TERLEBIH DAHULU
NasdaqGS:Rasio PE APP pada November 2025
Rasio PE menceritakan satu hal, namun bagaimana jika peluang sebenarnya ada di tempat lain? Temukan 1.403 perusahaan di mana orang dalam bertaruh besar pada pertumbuhan yang eksplosif.
Tingkatkan Pengambilan Keputusan Anda: Pilih Narasi AppLovin Anda
Sebelumnya kami telah menyebutkan bahwa ada cara yang lebih baik untuk memahami penilaian, jadi mari perkenalkan Anda pada Narasi. Narasi adalah alat sederhana dan ampuh yang memungkinkan Anda menceritakan kisah di balik sebuah perusahaan dengan menghubungkan perspektif unik Anda tentang model bisnis AppLovin, peluang pertumbuhan, dan risiko dengan perkiraan keuangan nyata dan perkiraan nilai wajar.
Daripada mengandalkan metrik yang kaku saja, Narasi memungkinkan Anda menjelaskan alasan di balik asumsi Anda mengenai pendapatan, penghasilan, dan margin keuntungan di masa depan. Narasi menjembatani kesenjangan antara kisah perusahaan dan angka-angka, membantu Anda melihat bagaimana pandangan yang berbeda menghasilkan nilai wajar yang sangat berbeda.
Dengan jutaan investor yang menggunakan halaman Komunitas Simply Wall St, Narasi mudah diakses dan diperbarui dalam hitungan menit. Apakah Anda yakin ekspansi internasional AppLovin dan kemajuan AI akan mendorong pertumbuhan berkelanjutan, atau Anda khawatir bahwa meningkatnya persaingan dan risiko peraturan dapat memperlambat pendapatan, Anda dapat membuat atau meninjau Narasi yang sesuai dengan pandangan Anda.
Dengan membandingkan Nilai Wajar Narasi Anda dengan harga saat ini, Anda mendapatkan sinyal yang jelas dan dinamis mengenai apakah AppLovin terlihat seperti beli, tahan, atau jual. Sinyal ini diperbarui secara otomatis ketika hasil perusahaan baru dan berita pasar masuk. Misalnya, saat ini di platform, Narasi komunitas melihat nilai wajar AppLovin mulai dari bullish sebesar $650 hingga $250, yang menunjukkan bagaimana pandangan Anda dapat membentuk keputusan Anda.
Apakah menurut Anda masih ada cerita lain tentang AppLovin? Kunjungi Komunitas kami untuk melihat apa yang dikatakan orang lain!
NasdaqGS:Nilai Wajar Komunitas APP per November 2025
Artikel oleh Simply Wall St ini bersifat umum. Kami memberikan komentar berdasarkan data historis dan perkiraan analis hanya dengan menggunakan metodologi yang tidak memihak dan artikel kami tidak dimaksudkan sebagai nasihat keuangan. Ini bukan merupakan rekomendasi untuk membeli atau menjual saham apa pun, dan tidak mempertimbangkan tujuan Anda, atau situasi keuangan Anda. Kami bertujuan untuk memberikan Anda analisis terfokus jangka panjang yang didorong oleh data fundamental. Perhatikan bahwa analisis kami mungkin tidak memperhitungkan pengumuman perusahaan terbaru yang sensitif terhadap harga atau materi kualitatif. Simply Wall St tidak memiliki posisi di saham mana pun yang disebutkan.
Baru: Kelola Semua Portofolio Saham Anda di Satu Tempat
Kami telah membuat pendamping portofolio utama bagi investor saham, dan itu gratis.
• Hubungkan Portofolio dalam jumlah tak terbatas dan lihat total Anda dalam satu mata uang • Waspadai Tanda Peringatan atau Resiko baru melalui email atau ponsel • Lacak Nilai Wajar saham Anda
Coba Portofolio Demo Gratis
Punya tanggapan tentang artikel ini? Khawatir dengan isinya? Hubungi kami secara langsung. Atau, kirim email ke editorial-team@simplywallst.com
Workiva (WK) menyampaikan pembaruan kuartal ketiga yang kuat, melampaui ekspektasi pendapatan dan pendapatan sekaligus meningkatkan prospeknya untuk sisa tahun ini. Perusahaan juga mengonfirmasi penunjukan Chief Revenue Officer baru untuk mendukung pertumbuhan yang berkelanjutan.
Lihat analisis terbaru kami untuk Workiva.
Harga saham Workiva telah meningkat tajam dalam tiga bulan terakhir, naik hampir 21%, karena hasil kuartalan yang optimis dan perubahan kepemimpinan telah membantu memulihkan kepercayaan investor setelah awal tahun yang sulit. Bahkan setelah memperhitungkan momentum terkini, total keuntungan pemegang saham dalam satu tahun masih turun 6% dan masih di bawah rekam jejak jangka panjang. Namun, perpaduan antara pertumbuhan yang kuat dan peningkatan eksekusi mulai menggeser sentimen ke arah positif.
Jika Anda penasaran dengan saham apa lagi yang mendapatkan daya tarik, sekarang adalah waktu yang tepat untuk memperluas pencarian Anda dan menemukan saham-saham yang berkembang pesat dengan kepemilikan orang dalam yang tinggi.
Setelah peningkatan laba yang kuat dan panduan ke atas, apakah harga saham Workiva saat ini merupakan titik masuk yang menarik bagi investor? Atau apakah pasar sudah memperhitungkan prospek pertumbuhan perusahaan yang semakin cepat?
Narasi Paling Populer: 8,8% Diremehkan
Dengan narasi Workiva yang paling banyak diikuti menempatkan nilai wajar pada $97,60 versus penutupan baru-baru ini sebesar $89, saham tersebut diposisikan sebagai undervalued menurut konsensus. Penilaian ini menyoroti keterputusan antara proyeksi pertumbuhan yang kuat dan harga saham saat ini, sehingga mengundang kajian lebih dekat terhadap asumsi-asumsi yang mendasarinya.
Fokus Workiva pada kontrak besar dan platform multi-solusi, terutama dengan perusahaan besar, bertujuan untuk mendorong pendapatan melalui perluasan akun dan nilai kontrak yang lebih tinggi. Permintaan yang kuat terhadap keberlanjutan dan solusi yang disempurnakan dengan AI, serta upaya ekspansi global, diharapkan dapat meningkatkan pendapatan berlangganan dan meningkatkan efisiensi operasional.
Baca narasi lengkapnya.
Penasaran asumsi apa yang membenarkan nilai wajar yang menarik tersebut? Narasi paling populer berpusat pada ekspansi pendapatan yang cepat, peningkatan margin keuntungan, dan perkiraan ambisius yang menantang ekspektasi konvensional terhadap bisnis perangkat lunak cloud. Target keuangan berani manakah yang menurut para analis akan mengubah kerugian saat ini menjadi keuntungan pertumbuhan di masa depan? Selami untuk mengungkap angka dan logika di balik kisah penilaian ini.
Hasil: Nilai Wajar $97,60 (DIBAWAH NILAI)
Bacalah narasinya secara lengkap dan pahami apa yang ada di balik ramalan tersebut.
Namun, ketidakpastian peraturan yang tidak terduga di Eropa atau perubahan kondisi makroekonomi global dapat menantang prospek pertumbuhan Workiva dan memberikan tekanan pada penilaian jangka pendek.
Cari tahu tentang risiko utama narasi Workiva ini.
Bangun Narasi Workiva Anda Sendiri
Jika Anda melihat sesuatu secara berbeda atau lebih suka menggali sendiri angka-angkanya, Anda dapat menyusun pandangan Anda sendiri hanya dalam beberapa menit, jadi mengapa tidak Lakukan dengan cara Anda sendiri
Titik awal yang baik untuk penelitian Workiva Anda adalah analisis kami yang menyoroti 2 imbalan utama dan 1 tanda peringatan penting yang dapat memengaruhi keputusan investasi Anda.
Mencari Lebih Banyak Ide Investasi?
Jangan batasi peluang Anda. Ambil pendekatan yang lebih cerdas dengan memilih sendiri saham menggunakan alat penyaring canggih yang dibuat untuk hasil nyata. Investasi yang tepat hanya berjarak satu klik saja.
Artikel oleh Simply Wall St ini bersifat umum. Kami memberikan komentar berdasarkan data historis dan perkiraan analis hanya dengan menggunakan metodologi yang tidak memihak dan artikel kami tidak dimaksudkan sebagai nasihat keuangan. Ini bukan merupakan rekomendasi untuk membeli atau menjual saham apa pun, dan tidak mempertimbangkan tujuan Anda, atau situasi keuangan Anda. Kami bertujuan untuk memberikan Anda analisis terfokus jangka panjang yang didorong oleh data fundamental. Perhatikan bahwa analisis kami mungkin tidak memperhitungkan pengumuman perusahaan terbaru yang sensitif terhadap harga atau materi kualitatif. Simply Wall St tidak memiliki posisi di saham mana pun yang disebutkan.
Penilaian itu rumit, namun kami di sini untuk menyederhanakannya.
Temukan apakah Workiva mungkin dinilai terlalu rendah atau terlalu tinggi dengan analisis terperinci kami yang menampilkan estimasi nilai wajar, potensi risiko, dividen, insider trade, dan kondisi keuangannya.
Akses Analisis Gratis
Punya tanggapan tentang artikel ini? Khawatir dengan isinya? Hubungi kami secara langsung. Atau, kirim email ke editorial-team@simplywallst.com
Over the past few months, I have been helping software developers, solutions architects, ML and DevOps engineers, and even Scrum Masters learn Azure Machine Learning and prepare for cloud-based data science certifications.
One of the most respected data science certifications today is the DP-100 Microsoft Certified Azure Data Scientist Associate.
To pass the DP-100 certification, you should use DP-100 exam simulators, review DP-100 test questions, and take online DP-100 practice exams like this one.
Keep practicing until you can consistently answer Azure ML and data science lifecycle questions with confidence.
These DP-100 questions are focused on commonly misunderstood Azure Machine Learning concepts. If you can answer these correctly, you are well on your way to passing the certification.
These are not DP-100 exam dumps. They are representative of the style and reasoning required for the real exam, not copies of actual questions.
Now here are the DP-100 practice questions and answers. Good luck!
DP-100 Certification Questions & Answers
Contoso Automated Machine Learning can handle several types of modeling tasks. Apart from regression models and classification models, which three additional problem categories does Contoso AutoML provide support for? (Choose 3)
❏ A. Natural language processing and text analytics
❏ B. Anomaly detection for identifying outliers
❏ C. Time series forecasting for sequential data
❏ D. Computer vision for image and object analysis
❏ E. Recommendation systems for personalized suggestions
Aurora Data Solutions needs a shared data engineering and data science platform that supports Python and Scala development, enables automated pipeline orchestration, isolates workloads for different teams, and scales across a compute cluster. What deployment approach on Google Cloud best meets these requirements?
❏ A. Databricks on Google Cloud with Cloud Composer
❏ B. Cloud Dataflow with Cloud Scheduler
❏ C. Cloud Dataproc with Cloud Composer
❏ D. Cloud Dataproc with Google Kubernetes Engine for orchestration
You are consulting for Orin Health Systems on a prototype called Titania that was developed by Lyra and Nova. The research director discovers an Azure Machine Learning experiment that will train on a very small dataset of about eight gigabytes and he wants to avoid paying for cloud virtual machine time. Lyra needs to pick a compute target to run the training while ensuring no ongoing Azure VM costs are incurred. Which compute resource should Lyra choose for the training workload?
❏ A. Compute instance
❏ B. Inference cluster
❏ C. Compute cluster
❏ D. Local workstation
The Aurora Room is a high end nightclub in Meridian that also operates as a cover for the enterprises of Victor Marlowe. You were engaged to consult on IT and the venue has deployed Microsoft Azure for its data workflows. A data scientist is working with a numerical table that contains missing entries across multiple columns and must impute those gaps while preserving every feature in the dataset for analysis. The team intends to use the Last Observation Carried Forward method to populate missing values. Does this tactic satisfy the requirement to include all records and keep the feature dimensionality unchanged?
❏ A. Using Last Observation Carried Forward is not an appropriate approach for imputing the missing entries in this dataset
❏ B. Applying Last Observation Carried Forward is an acceptable technique to impute the missing values while keeping the feature set unchanged
Which components are added to the visual pipeline editor by the Create Inference Pipeline action? (Choose 2)
A computer vision team at Meridian Labs trains convolutional neural networks to extract image features and then pass them to classifiers for label prediction. The team wants to reduce overfitting where the model memorizes training images and fails to perform on unseen examples. Engineers recommend adding a layer that randomly deactivates portions of the feature maps during training to stop the network from depending on particular patterns. Which layer type matches this description?
Scenario Cedar Labs engaged you to advise its machine learning group as they start using HorovodRunner for distributed model training on Azure Databricks. The engineers want to execute a training run on a single node for validation. Which np parameter value should they set to run Horovod on a single node?
❏ A. np=1
❏ B. np=’1′
❏ C. np=2
❏ D. np=(1)
❏ E. np=.1
❏ F. np=-1
When performing hyperparameter optimization with Bayesian methods which statement is accurate?
❏ A. Bayesian tuning always locates the global best hyperparameter set and it is the slowest method
❏ B. Using Bayesian sampling on AI Platform requires that model artifacts are stored in Cloud Storage
❏ C. Bayesian optimization can be combined with an early stopping policy
❏ D. Bayesian methods are inherently the slowest tuning strategy across every dataset and model type
In a data platform context what distinguishes a data store from a data asset?
❏ A. Cloud Storage
❏ B. A data store is the physical or managed location holding data and a data asset is a logical table or file that represents a data set
❏ C. A data store is a mechanism to publish data externally while a data asset is compute capacity used for training models
❏ D. A data asset refers to storage locations and a data store refers to processing engines
Which method of passing a registered dataset supplies the training script with the dataset’s workspace identifier so the script can fetch the dataset from the run context?
Summit Analytics uses Azure Role Based Access Control to regulate access to its Azure Machine Learning workspace and team members are assigned roles that determine what assets they can access and which actions they may perform. One authentication workflow is described as follows. It uses an Azure Active Directory user account for authentication either by manual sign in or by obtaining an authentication token. It is primarily used during experimentation and iterative development and it enables per user control over access to resources such as deployed web endpoints. Which authentication workflow matches this description?
❏ A. Service principal
❏ B. Managed identity
❏ C. Interactive
❏ D. Azure CLI session
A retail analytics team at NovaMart is running an Automated Machine Learning experiment in Azure Machine Learning and wants to set conditions that will stop the run automatically. What two exit conditions can be configured to terminate the AutoML process early?
❏ A. Compute resource usage limit and score threshold
❏ B. Maximum training duration and target metric threshold
❏ C. Cluster node quota and error rate limit
❏ D. Maximum concurrent iterations and failure threshold
A data consultancy named Arcadia Analytics runs the Azure Machine Learning SDK on an Azure virtual machine and wants the VM to authenticate to the workspace without storing credentials in code or prompting a user. The compute pools used for training should also be able to use the same approach when executing jobs. Which authentication workflow matches this description?
Coastal Harbor Credit Union is shifting its transaction systems to Microsoft Azure and the leadership has engaged you as the principal data scientist to guide their team. The group is building an automated machine learning based classification system to flag credit card fraud and the training set is very skewed with roughly one fraudulent record for every forty legitimate transactions. The head of analytics wants your recommendation on which primary evaluation metric to use given this class imbalance. Which metric should you recommend?
❏ A. normalized_root_mean_squared_error
❏ B. area_under_precision_recall_curve
❏ C. AUC_weighted
❏ D. Accuracy
❏ E. spearman_correlation
Is automated machine learning primarily intended for experienced data scientists while the guided model builder is aimed at non-experts?
A data science team at Nova Analytics is assembling a modular training workflow in Azure Machine Learning and the workflow contains multiple custom components that must receive configuration values and parameters from each run. Which strategy should the team use to define these parameters so each job execution can be configured appropriately?
❏ A. Embed fixed parameter values inside every component source to avoid external configuration
❏ B. Declare only pipeline level parameters and apply the same values to all components without per component overrides
❏ C. Place parameter definitions inside each component script so each run can supply custom values
❏ D. Map pipeline parameters to Azure ML component inputs at runtime so runs supply values to each component
A data science team at Contoso is training an image classification model using pictures stored in an Azure Data Lake Storage Gen2 account. When they create a data asset that points to that storage what asset type should they pick to correctly reference the collection of image files?
❏ A. Image
❏ B. Recording
❏ C. File
❏ D. Folder
RapidShip Logistics operates out of its headquarters in Milan Italy and it has just hired Selena Torres as a data scientist. Selena needs permission to submit a script as a job to an Azure Machine Learning workspace. Which role assignment will grant Selena the permissions required to access the workspace and run jobs?
You are working in a CityTransit Python notebook and you have a Pandas dataframe named lateness_df that contains daily commuter rail lateness records with columns year month day train_no and delay_minutes. How would you compute the average of delay_minutes?
❏ A. lateness_df[‘delay_minutes’].median()
❏ B. Avg(lateness_df[‘delay_minutes’])
❏ C. lateness_df[‘delay_minutes’].mean()
❏ D. np.mean(lateness_df)
How can an organization evaluate fairness and reduce ethnicity related bias in a binary admissions classifier developed with Azure Machine Learning?
❏ A. Apply adversarial debiasing or reweighting during training
❏ B. Measure and compare acceptance rates and predictive performance metrics across ethnic groups
❏ C. Remove ethnicity from the dataset
In Orion Machine Learning Studio which item is not presented as an asset or shown on a screen in the interface?
❏ A. Endpoints
❏ B. User Directory
❏ C. Data
❏ D. Jobs
The Falcon Collective is a regional analytics consortium seeking advice on Microsoft Azure. Their lead engineer has published a pipeline and wants to use the Schedule.create method so the pipeline runs weekly. Before configuring the weekly cadence which object must the team create first?
What must a data scientist have configured to connect from a local Python environment to a CloudWorks machine learning workspace using the Python SDK?
❏ A. A Compute Engine virtual machine with CPU or GPU resources
❏ B. A local workspace configuration file and invoking Workspace.from_config in the Python SDK
❏ C. A Google Cloud service account with application default credentials
❏ D. An App Engine deployment with environment variables set for the workspace
A data engineer at Meridian Analytics is assembling a pipeline in Azure Machine Learning Studio Designer and they need to remove extreme values from a single feature column in a dataset. Which Designer component should they choose?
Which feature scaling technique transforms continuous variables so they have a mean of zero and a standard deviation of one?
❏ A. MinMax normalization
❏ B. Z score standardization
❏ C. Robust scaling with median and interquartile range
❏ D. Log transformation
The Harbor Chronicle is a regional news startup that has engaged you to streamline its model training workflows and the lead engineer Alex Rivera configured Azure Machine Learning Hyperdrive with a parameter search defined as param_sampling = RandomParameterSampling({ “learning_rate”: normal(12,4), “dropout_prob”: uniform(0.02,0.08), “batch_size”: choice(32,64,128,256), “hidden_layers”: choice(range(2,6)) }) What statements about how Hyperdrive will sample these hyperparameters are correct?
❏ A. Defining sampling this way will exhaustively evaluate every combination of the parameters
❏ B. Random values for the learning_rate parameter will be sampled from a normal distribution with a mean of 12 and a standard deviation of 4
❏ C. The dropout_prob parameter will only ever be either 0.02 or 0.08
❏ D. The hidden_layers parameter will draw values from a normal distribution with a mean of 3 and a standard deviation of 5
Horizon Materials a UK chemical manufacturer headquartered in Manchester operates facilities across several countries and employs many technicians. For a computer vision project you and a Horizon technician must detect and extract the precise outlines of separate items inside images using Azure AutoML. Which computer vision model in Azure AutoML should you select to achieve this outcome?
❏ A. Multi-label image classification
❏ B. Object detection
❏ C. Instance segmentation
❏ D. Multi-class image classification
A data science group at Contoso Analytics wants to connect Azure Machine Learning to an automated build and release workflow using Azure DevOps so that training runs start automatically when code is pushed to the repository. Which method should they implement?
❏ A. Use Azure Event Grid to listen for repository push events and start training via webhooks
❏ B. Set up an Azure DevOps pipeline with a commit trigger that invokes Azure Machine Learning training runs
❏ C. Manually start training jobs from the Azure Machine Learning studio after each code change
❏ D. Configure recurring scheduled runs in Azure Machine Learning that run regardless of repository changes
A data science group at BrightAnalytics has deployed a model as a real time service on Azure Kubernetes Service and they use the Azure ML SDK to examine the deployment. The following Python code snippet is used to interact with an AKS hosted web service python from azureml.core.webservice import AksWebservice service = AksWebservice(name = ‘image-classifier-v2’, workspace = ws) print(service.state) What does this code do when investigating a deployed Azure Machine Learning service?
❏ A. Retrieves recent service logs from the container to diagnose errors
❏ B. Performs an internal error inspection on the AksWebservice object for exceptions
❏ C. Prints the current state of the AKS deployed web service
❏ D. Queries historical availability metrics for the service in the workspace
Which classification outcome describes an instance that is truly positive and is predicted as positive by the model?
❏ A. False Negative
❏ B. True Positive
❏ C. Precision
A data scientist at Contoso Data Labs is using the Azure Machine Learning Python SDK v2 to run automated machine learning for a regression problem, and the dataset contains missing values and categorical columns with a small set of categories. Which enum from the automl package should be used to explicitly manage automatic imputation and categorical encoding during the AutoML run?
A data scientist at Nimbus Analytics needs to separate a dataset into two distinct parts inside the Contoso Machine Learning Studio workspace for model training and validation. Which module should they use to perform this split?
Scenario: Meridian Data is a regional logistics analytics company founded by Clara Reyes and it offers route optimization fleet monitoring and delivery analytics. To modernize their analytics stack Clara adopted Microsoft Azure and hired you to consult on model evaluation practices for a regression project. The analytics team is discussing Mean Squared Error as an evaluation metric. Which of the following statements about Mean Squared Error is correct? (Choose 2)
❏ A. MSE can be negative for models that systematically underpredict
❏ B. A higher MSE denotes a better performing model
❏ C. An MSE of zero indicates a perfect fit
❏ D. MSE values are always greater than or equal to zero
Scenario: Cloudbridge Recruiting is a senior talent firm led by CEO Mara Finch and based in Brooklyn New York. The technology team is preparing to publish a new credit risk model as a batch endpoint and they need guidance on the proper way to load the model inside their batch scoring script. Which method should the scoring script use to load the model before processing mini batches?
❏ A. run
❏ B. azureml_main
❏ C. init
❏ D. main
How do regression models primarily differ from classification models in the type of output they produce?
❏ A. Regression predicts category labels
❏ B. Classification assigns discrete category labels while regression forecasts continuous numeric values
❏ C. Azure Machine Learning
Which query language does Contoso Data Explorer use to express its data retrieval and analytics statements?
Crescent Robotics operates from Lakeside Park in Chicago and it is expanding quickly which has created new IT priorities that the lead engineer has asked you to address. A group of interns have minimal experience with Azure Machine Learning and they have requested a concise description. Which of the following key points should you explain to them?
❏ A. A Windows desktop application that lets you build machine learning models with a drag and drop interface for virtual machines
❏ B. Vertex AI
❏ C. A cloud based platform for running and operationalizing machine learning solutions at scale
❏ D. A Python library meant to replace Scikit Learn PyTorch and TensorFlow
Dr. Elena Voss leads a data science group at Nova Dynamics which was founded by Marcus Lin and they are using Microsoft Azure Machine Learning automated experiments to pick the model with the highest AUC_weighted score. Which AutoMLConfig parameter should they configure to optimize for that metric?
❏ A. task=’AUC_weighted’
❏ B. compute_target=’AUC_weighted’
❏ C. primary_metric=’AUC_weighted’
❏ D. label_column_name=’AUC_weighted’
A retail banking startup plans to deploy a model for immediate transaction decisions and the engineering team must choose between an Azure online endpoint and batch scoring. Which situation most strongly supports deploying the model to an Azure online endpoint?
❏ A. Scheduled overnight scoring of a 25 TB transaction archive
❏ B. Hosting the model on Azure Kubernetes Service for gradual canary deployments
❏ C. Producing monthly sales performance analyses for stakeholder review
❏ D. Real time credit card fraud scoring that requires millisecond response times
Which of the following methods can be used to transfer data into Azure Blob Storage for use in model training? (Choose 3)
EdgeWorks Analytics uses Azure Machine Learning and teams can interact with the service using purpose built graphical tools or by using programmatic interfaces. Which approaches allow engineers to manage assets inside an Azure Machine Learning workspace? (Choose 2)
❏ A. Azure portal
❏ B. Azure Designer
❏ C. Application Programming Interface
❏ D. Azure Machine Learning Studio
❏ E. Azure Application Gateway
❏ F. Azure Connect
How can you confirm that a predictive model does not produce biased results across different racial groups?
❏ A. Vertex AI Model Evaluation
❏ B. Omit the race attribute from the training data
❏ C. Evaluate fairness and accuracy metrics across demographic groups
❏ D. Train the model using data from a single racial group
Orion Dynamics is an aerospace analytics firm that has adopted Azure Machine Learning to train a convolutional neural network for image classification. A data scientist has a training script that requires CUDA capable GPUs and needs to submit the experiment within the Azure Machine Learning workspace. Available compute resources include a corporate laptop that blocks additional software installation, a compute instance named dev-workstation with 2 vCPUs and 10 GB of memory, an Azure Machine Learning compute target named cpu-pool with ten CPU nodes, and an Azure Machine Learning compute target named gpu-pool with five nodes that provide CPUs and NVIDIA GPUs. Which compute resource should the data scientist choose to execute the training script to minimize total model training time?
❏ A. dev-workstation compute instance
❏ B. cpu-pool compute target
❏ C. gpu-pool compute target
❏ D. corporate laptop
A retail analytics startup named Meridian Analytics has deployed a trained model as a service on a managed Kubernetes cluster of their cloud machine learning platform. Production client applications will not include the platform SDK. How will those client applications typically invoke the deployed model service?
❏ A. gRPC interface
❏ B. SOAP interface
❏ C. JSON interface
❏ D. REST interface
Which Azure Machine Learning run logging methods should be used respectively to log a scalar observation, a matplotlib figure, and a dataframe or dictionary?
❏ A. run.log_table then run.log_image then run.log
❏ B. run.log then run.log_image then run.log_table
❏ C. run.log then run.log_table then run.log_image
❏ D. run.log_row then run.log_figure then run.log_table
Convolutional neural networks are a standard choice for image understanding at a fictional company called PixelWorks which builds visual recognition systems. These architectures extract spatial features through specialized layers and then pass those features into a dense network for final prediction. Which of the following are valid layer types in a convolutional neural network? (Choose 5)
❏ A. Flattening layers
❏ B. Normalization layers
❏ C. Dropout layers
❏ D. Convolution layers
❏ E. Pooling layers
❏ F. Fully connected layers
Rafferty’s Eats is a regional quick service chain that competes with Griddle King and they have hired you to advise on Azure data science projects, and you are leading a meeting on model training. The team built a regression model using scikit-learn and when tested on unseen data it yielded an R-squared score of 0.93. What does that metric indicate about the model’s performance?
❏ A. On average predictions exceed actual values by 0.93 units
❏ B. The model explains about 93 percent of the variance in the target variable
❏ C. The model achieves 93 percent accuracy
❏ D. Inputs with larger values always produce larger outputs
Maya Chen at Meridian Analytics is building a new Azure Machine Learning pipeline that uses structured tables which require frequent access during model training and validation. Using Azure ML SDK v2 which data asset type should she register to provide efficient access and processing?
❏ A. FileDataset
❏ B. uri_folder
❏ C. TabularDataset
❏ D. mltable
Maya Reyes is the principal engineer at the cloud media startup Nebula Systems and she is leading the rollout of Microsoft Azure for the analytics group. She needs to register an Azure Blob container as a datastore for Azure Machine Learning using the Azure ML SDK v2. Which class or method should she use to register the Blob storage as a datastore?
❏ A. AzureFileDatastore
❏ B. ml_client.datastores.create_or_update
❏ C. AzureDataLakeGen2Datastore
❏ D. AzureBlobDatastore
How do you run an Azure Machine Learning training job on a scalable compute cluster using a designated Python environment while taking input from an Azure Blob storage data asset?
❏ A. Use a compute instance with the platform default Python environment and access Blob storage directly from the script
❏ B. Run on Azure Batch with a custom VM image and copy Blob data into the job image before execution
❏ C. Register a custom Python environment and target an Azure ML compute cluster while referencing the Azure Blob data asset
SwiftParcel Logistics hired Rachel Morgan as a data scientist at its new headquarters in Valencia Spain and Rachel trains a regression model and she wants to record the root mean squared error within the MLflow experiment run for later monitoring and comparison. Which function should she call to log the RMSE?
❏ A. mlflow.log_artifact()
❏ B. mlflow.autolog()
❏ C. mlflow.log_param()
❏ D. mlflow.log_metric()
Scenario: Meridian Analytics is a private firm controlled by Priya Rao and it reports an estimated market capitalization near forty-five million dollars. The business formed after the Meridian Foundation and Priya serves as chief executive officer and board chair. She asked for advice because her IT staff plans to adopt Microsoft Azure Machine Learning for upcoming data projects. During a group workshop you are explaining the notebook file types that Databricks accepts. Which file extension does Databricks support for notebook export and import?
❏ A. .spark
❏ B. Cloud Dataproc
❏ C. DBC
❏ D. .dbr
Scenario: Arcadia Robotics, founded by Elena Park, has expanded into a leading industrial robotics company by integrating Azure Machine Learning into its projects. For a new model training workflow Elena needs to register structured data that is distributed across many text files so her team can access it with the fewest steps possible. Which type of data asset should she register to accomplish this?
❏ A. A single CSV file hosted at a public HTTPS address
❏ B. A folder of image files meant for computer vision experiments
❏ C. An MLTable data asset that references the collection of text files and defines a tabular schema
❏ D. A single large video file stored in blob storage
A fintech startup called NorthBridge is training a loan approval model and wants to make sure the model does not produce unfair outcomes across racial groups. What validation steps should the team take to confirm the model treats different races fairly?
❏ A. Train multiple models each on data from only one racial group
❏ B. Evaluate fairness and performance metrics for each racial group and apply mitigation techniques when disparities appear
❏ C. Cloud DLP
❏ D. Remove the race or ethnicity column from the training data
Which method executes the training code on Databricks and enables automated MLflow tracking during hyperparameter tuning?
Azure Data Scientist Questions Answered
Contoso Automated Machine Learning can handle several types of modeling tasks. Apart from regression models and classification models, which three additional problem categories does Contoso AutoML provide support for? (Choose 3)
✓ A. Natural language processing and text analytics
✓ C. Time series forecasting for sequential data
✓ D. Computer vision for image and object analysis
The correct options are Natural language processing and text analytics, Time series forecasting for sequential data, and Computer vision for image and object analysis.
Natural language processing and text analytics is included because the AutoML workflow can automate text preprocessing, feature extraction, and model selection for language tasks such as classification and entity extraction, which makes text analytics a supported category beyond standard classification and regression.
Time series forecasting for sequential data is included because AutoML can build and evaluate forecasting pipelines that handle temporal features, windowing, and forecasting metrics, and it automates the selection of models and hyperparameters for sequential prediction tasks.
Computer vision for image and object analysis is included because AutoML extends to image problems and can automate image preprocessing, model training, and evaluation for tasks like image classification and object detection, which makes vision a distinct supported category.
Anomaly detection for identifying outliers is incorrect for this question because it was not listed as one of the three additional categories in the prompt. Although anomaly detection is a valid machine learning task, it is not one of the selected answers here.
Recommendation systems for personalized suggestions is incorrect because recommendation models were not included among the three additional categories. Recommender systems are a separate area and they were not part of the correct answer set.
Read the question carefully and focus on the specific categories named. Look for common AutoML extensions such as vision, text, and time series when answers extend beyond regression and classification.
Aurora Data Solutions needs a shared data engineering and data science platform that supports Python and Scala development, enables automated pipeline orchestration, isolates workloads for different teams, and scales across a compute cluster. What deployment approach on Google Cloud best meets these requirements?
The correct answer is Cloud Dataproc with Cloud Composer.
Cloud Dataproc provides a managed Spark and Hadoop environment that supports both Python and Scala development and it can scale across a compute cluster with autoscaling and cluster pooling. Cloud Composer supplies managed Apache Airflow for automated pipeline orchestration and it can submit and manage Dataproc jobs while handling DAGs, retries, and dependencies. Together they allow teams to isolate workloads by using separate or ephemeral clusters and they meet the needs of a shared data engineering and data science platform.
The combination is native to Google Cloud so it integrates with IAM, Cloud Storage, logging, and monitoring. Using Cloud Dataproc with Cloud Composer reduces operational overhead compared with building and maintaining a custom orchestration layer and it fits common enterprise patterns for scalable, multi team analytics.
Databricks on Google Cloud with Cloud Composer could support Python and Scala and Composer can orchestrate jobs but Databricks is a third party managed platform rather than the native Google Cloud managed Spark service. That difference brings additional licensing and integration considerations that make it a less likely correct choice on a GCP focused architecture exam.
Cloud Dataflow with Cloud Scheduler is not the best fit because Cloud Dataflow is an Apache Beam service optimized for streaming and batch transforms and it does not provide first class Scala based Spark runtimes. Also Cloud Scheduler is a simple cron style trigger and it does not offer the DAG based orchestration, dependency handling, and operational features that Composer provides.
Cloud Dataproc with Google Kubernetes Engine for orchestration would work in principle but using Google Kubernetes Engine for orchestration requires you to build and operate a custom orchestration layer and it adds significant operational overhead. The managed Airflow in Cloud Composer is a better fit for DAG oriented pipelines and integrates directly with Dataproc job APIs.
When a question lists Spark or Scala support plus cluster scaling and DAG orchestration prefer the native GCP combination of Cloud Dataproc and Cloud Composer for tighter integration and lower operational overhead.
You are consulting for Orin Health Systems on a prototype called Titania that was developed by Lyra and Nova. The research director discovers an Azure Machine Learning experiment that will train on a very small dataset of about eight gigabytes and he wants to avoid paying for cloud virtual machine time. Lyra needs to pick a compute target to run the training while ensuring no ongoing Azure VM costs are incurred. Which compute resource should Lyra choose for the training workload?
The correct option is Local workstation.
A Local workstation runs the training on the developer’s own machine so no Azure virtual machines are started and no cloud VM time is billed. With a small dataset of about eight gigabytes it is practical to run the experiment locally and meet the requirement to avoid paying for cloud VM time.
Choosing a Local workstation does mean you rely on local CPU or GPU resources and you may trade off scalability and managed reproducibility, but it directly addresses the constraint about ongoing Azure VM costs.
Compute instance is a managed cloud VM provided by Azure Machine Learning for interactive development and it will incur VM charges while running and sometimes while provisioned, so it does not avoid cloud VM costs.
Inference cluster is intended for serving deployed models in production rather than for training experiments, and it uses cloud compute resources so it would incur VM time charges.
Compute cluster is a scalable set of cloud VMs used for distributed training and batch jobs and even though it can autoscale it still consumes cloud VM time during jobs so it would not meet the requirement to avoid paying for cloud virtual machine time.
When a question requires avoiding cloud VM charges look for options that run locally. Consider whether the dataset and model can reasonably fit on a local machine before choosing that option.
The Aurora Room is a high end nightclub in Meridian that also operates as a cover for the enterprises of Victor Marlowe. You were engaged to consult on IT and the venue has deployed Microsoft Azure for its data workflows. A data scientist is working with a numerical table that contains missing entries across multiple columns and must impute those gaps while preserving every feature in the dataset for analysis. The team intends to use the Last Observation Carried Forward method to populate missing values. Does this tactic satisfy the requirement to include all records and keep the feature dimensionality unchanged?
Applying Last Observation Carried Forward is an acceptable technique to impute the missing values while keeping the feature set unchanged is the correct option.
Last Observation Carried Forward works by filling each missing entry with the most recent observed value in the same column. Because it only replaces missing cells and does not add or remove rows or columns it preserves every record and keeps the feature dimensionality unchanged. This makes the approach acceptable when the data have a meaningful ordering, such as time series data, and when carrying forward prior values is a reasonable assumption.
That said, Last Observation Carried Forward can introduce bias if values tend to change over time or if missingness is not random. Analysts should verify that the method s assumptions hold and consider alternative imputations when dynamics or missingness patterns make carry forward inappropriate.
Using Last Observation Carried Forward is not an appropriate approach for imputing the missing entries in this dataset is incorrect because it states an absolute rejection of the method. The statement is too strong because Last Observation Carried Forward does meet the specific requirements to keep all records and maintain feature dimensionality, even though it may not always be the best statistical choice without further context.
When a question focuses on preserving records and feature count think about whether the imputation changes rows or columns. Use Last Observation Carried Forward for ordered data when carrying values forward is defensible and call out potential bias in your answer.
Which components are added to the visual pipeline editor by the Create Inference Pipeline action? (Choose 2)
Web service output and Web service input are correct because those are the modules that the Create Inference Pipeline action adds to the visual pipeline editor.
The action inserts a Web service input module to accept data at runtime and a Web service output module to return predictions when the pipeline is published as a web service. These modules define the interface for real time scoring and allow the designer pipeline to be deployed as an online endpoint.
The Batch inference option is incorrect because the Create Inference Pipeline action does not add a batch processing component. Batch inference is handled by separate jobs or pipelines for offline large scale scoring and is not the web service interface that this action creates.
When a question mentions creating an inference pipeline focus on what is needed to expose the pipeline as a real time service and look for options that mention Web service input or Web service output rather than batch processing.
A computer vision team at Meridian Labs trains convolutional neural networks to extract image features and then pass them to classifiers for label prediction. The team wants to reduce overfitting where the model memorizes training images and fails to perform on unseen examples. Engineers recommend adding a layer that randomly deactivates portions of the feature maps during training to stop the network from depending on particular patterns. Which layer type matches this description?
The correct option is Dropout layers.
Dropout layers randomly deactivate a subset of activations during training by setting them to zero so the model cannot rely on any single activation. This reduces co adaptation of neurons and helps prevent the network from memorizing training images so it generalizes better to unseen examples.
There are variants such as spatial dropout that drop entire feature channels in convolutional feature maps which is useful when working with CNNs and image data. Using a dropout layer is the standard recommendation when the described behavior is required.
Batch normalization layers normalize activations across the batch to stabilize and speed training and they are not designed to randomly deactivate parts of the network. They can provide some regularization but they do not implement the random dropping behavior described.
Flattening layers reshape feature maps into vectors so they can be fed to classifiers and they do not alter activations randomly. They only change the tensor shape and so they do not provide the randomized regularization behavior asked for.
Pooling layers downsample spatial dimensions to provide translational invariance and reduce resolution and they do not randomly deactivate units. Pooling selects or aggregates values and it is not a mechanism for randomly dropping activations during training.
Dense layers are fully connected layers that compute weighted sums and apply activations and they are not a method of randomly deactivating activations. Dropout is often applied to outputs of dense layers to regularize them but the dense layer itself does not perform dropout.
Convolutional layers apply learned filters across the input to extract local features and they do not randomly zero out activations as a regularization technique. There is a spatial dropout variant that targets convolutional feature maps but the convolutional layer itself is not the dropout mechanism.
When the question mentions randomly deactivates or sets activations to zero think of dropout. Match the described behavior to the layer purpose rather than similar sounding names.
Scenario Cedar Labs engaged you to advise its machine learning group as they start using HorovodRunner for distributed model training on Azure Databricks. The engineers want to execute a training run on a single node for validation. Which np parameter value should they set to run Horovod on a single node?
The correct option is np=-1.
np=-1 is the sentinel value used with HorovodRunner to run training on a single node in local mode on Databricks. Setting this numeric value tells HorovodRunner to run on the current node for validation rather than launching a multi node distributed job, so it is the appropriate choice for single node validation runs.
np=1 is incorrect because a plain numeric 1 is treated as an explicit process count and is not the special sentinel that forces single node local mode.
np=’1′ is incorrect because providing the value as a string is not the documented numeric sentinel and will not have the intended single node effect.
np=2 is incorrect because it requests two processes and therefore does not indicate a single node validation run.
np=(1) is incorrect because that expression resolves to the numeric value 1 and is not the documented sentinel value for single node execution.
np=.1 is incorrect because fractional values are not valid process counts and do not represent the single node sentinel.
When a parameter accepts special sentinel values like -1 check the official documentation for the exact semantics and use the numeric sentinel rather than a string or unconventional syntax.
When performing hyperparameter optimization with Bayesian methods which statement is accurate?
The correct answer is Bayesian optimization can be combined with an early stopping policy.
Bayesian optimization can be paired with early stopping rules so unpromising trials are ended early and resources are saved. Many hyperparameter tuning systems implement policies such as median stopping or successive halving together with Bayesian search and Google Cloud’s Vizier and Vertex AI support stopping policies for trials.
Bayesian tuning always locates the global best hyperparameter set and it is the slowest method is wrong because Bayesian methods are probabilistic search strategies and they do not guarantee finding the global optimum. They are often more sample efficient than naive methods but they are not universally the slowest approach.
Using Bayesian sampling on AI Platform requires that model artifacts are stored in Cloud Storage is incorrect because the choice of a sampling or optimization algorithm does not by itself mandate where artifacts are stored. Cloud Storage is commonly used for data and model artifacts on Google Cloud, but that is a platform detail rather than a property of Bayesian sampling. Also AI Platform has been succeeded by Vertex AI so newer exams are more likely to reference Vertex AI and Vizier.
Bayesian methods are inherently the slowest tuning strategy across every dataset and model type is incorrect because runtime and overall experiment time depend on the model, dataset, per trial cost, and implementation details. Bayesian methods often reduce the number of trials needed to reach a good result and so can reduce total tuning time even if they add some computational overhead per suggestion.
Watch for absolute words like always and requires in exam options. They often indicate incorrect statements because machine learning methods and cloud platforms have practical caveats and trade offs.
In a data platform context what distinguishes a data store from a data asset?
The correct answer is A data store is the physical or managed location holding data and a data asset is a logical table or file that represents a data set.
A data store is the actual place where data is persisted or managed and it can be an object store a file system a relational database or another managed storage service. The store is concerned with how and where bytes are held and protected.
A data asset is the logical representation of a dataset such as a table a file a view or a named dataset and it is what analysts and applications reference. Assets carry schema and metadata and they can span or be copied between different stores while keeping their logical identity.
Cloud Storage is incorrect because it names a specific storage service and not the conceptual distinction between a location and a logical dataset. Cloud Storage is an example of a data store and not the defining contrast with a data asset.
A data store is a mechanism to publish data externally while a data asset is compute capacity used for training models is incorrect because it mixes unrelated concepts. Publishing and compute capacity are separate concerns and do not capture the store versus asset difference.
A data asset refers to storage locations and a data store refers to processing engines is incorrect because it reverses the terms. A data asset is a logical dataset and a data store is the storage location and not a processing engine.
When choosing an answer look for wording that separates the physical location from the logical representation. Think where data lives versus what the dataset represents.
Which method of passing a registered dataset supplies the training script with the dataset’s workspace identifier so the script can fetch the dataset from the run context?
The correct option is Dataset passed as a script argument.
When you use Dataset passed as a script argument the training job receives a dataset reference that includes the workspace identifier so the script can fetch the registered dataset from the run context using the SDK. This approach provides an indirection that lets the script look up the dataset by name or id at runtime and then mount or download the actual files as needed.
Workspace datasets collection is simply the registry of datasets in the workspace and it does not by itself inject a dataset identifier into the script run context. You would need to query the workspace programmatically to retrieve a dataset reference which is not the same as having the run provide the identifier to the script.
Named input typically mounts or provides a direct path to the data for the job so the script receives a concrete data location rather than the workspace dataset identifier. Because it materializes access to the files it does not give the script the workspace id that the run context uses to fetch a registered dataset later.
Look for choices that pass a reference or id into the job when the question asks for a method that lets the script fetch the dataset from the run context. Options that mount or give a path usually do not provide the workspace identifier.
Summit Analytics uses Azure Role Based Access Control to regulate access to its Azure Machine Learning workspace and team members are assigned roles that determine what assets they can access and which actions they may perform. One authentication workflow is described as follows. It uses an Azure Active Directory user account for authentication either by manual sign in or by obtaining an authentication token. It is primarily used during experimentation and iterative development and it enables per user control over access to resources such as deployed web endpoints. Which authentication workflow matches this description?
Interactive is correct. This option describes signing in with an Azure Active Directory user account either by manual sign in or by obtaining a user authentication token and it is the workflow used during experimentation and iterative development that enables per user control over resources such as deployed web endpoints.
The described workflow depends on a human user to authenticate so that access can be governed by the user identity and RBAC assignments. During development and testing developers sign in interactively to acquire tokens and to exercise endpoints under their own permissions rather than using a shared or resource bound identity.
Service principal is incorrect because a service principal is an application identity used for noninteractive automation and service to service scenarios and it does not provide per user access control.
Managed identity is incorrect because a managed identity is assigned to an Azure resource rather than to a human user and it is intended for service to service authentication not manual sign in during experimentation.
Azure CLI session is incorrect because that refers specifically to authentication through the Azure command line tool which is typically used for scripting and administrative tasks and it is not the interactive SDK sign in workflow emphasized for iterative development in the question.
When a question mentions a human signing in or per user control during experimentation look for interactive authentication as the correct choice rather than identities intended for automation or resource bound use.
A retail analytics team at NovaMart is running an Automated Machine Learning experiment in Azure Machine Learning and wants to set conditions that will stop the run automatically. What two exit conditions can be configured to terminate the AutoML process early?
The correct answer is Maximum training duration and target metric threshold.
Azure Automated Machine Learning supports exit criteria that stop the experiment when a set time budget is exhausted and when a target model performance is reached. Setting a Maximum training duration enforces an overall time limit for the AutoML run so it ends when the allotted time elapses. Setting a target metric threshold instructs AutoML to stop the search once a model meets or exceeds the specified primary metric.
Compute resource usage limit and score threshold is incorrect because AutoML exit criteria focus on time and model performance rather than direct resource consumption limits, and the phrase score threshold is ambiguous compared to a configured primary metric goal.
Cluster node quota and error rate limit is incorrect because cluster node quotas are infrastructure constraints and not AutoML early termination settings, and AutoML does not use a generic error rate limit as a standard exit condition.
Maximum concurrent iterations and failure threshold is incorrect because maximum concurrent iterations controls parallelism and does not stop the entire experiment, and a failure threshold is not a standard AutoML exit criterion for ending runs early.
Read each option for whether it affects training time or model quality rather than infrastructure. Look for settings that specify a maximum duration or a target metric to identify valid AutoML exit conditions.
A data consultancy named Arcadia Analytics runs the Azure Machine Learning SDK on an Azure virtual machine and wants the VM to authenticate to the workspace without storing credentials in code or prompting a user. The compute pools used for training should also be able to use the same approach when executing jobs. Which authentication workflow matches this description?
Managed identity is correct because a managed identity allows the Azure virtual machine to obtain Azure Active Directory tokens without storing credentials in code or requiring a user to sign in, and the same identity approach can be used by training compute pools when they execute jobs.
Managed identity can be either system assigned or user assigned and you grant the identity the appropriate roles on the Azure Machine Learning workspace so the VM and compute resources can authenticate silently. The Azure SDKs and credential chains such as DefaultAzureCredential will pick up the managed identity automatically so there is no interactive sign in or secret to manage in code.
Service principal is incorrect because a service principal normally requires a client secret or certificate which must be stored or provisioned, so it does not meet the requirement to avoid stored credentials in code or prompts without additional secret management.
Azure CLI session is incorrect because it relies on a user signing in to the CLI and on an active session, which is not suitable for unattended VMs or compute pools running noninteractive jobs.
Interactive authentication is incorrect because it explicitly requires a user to complete an interactive sign in and therefore cannot provide the headless, credentialless authentication that the scenario demands.
When a question describes noninteractive, credentialless authentication for VMs and compute choose managed identities and remember that DefaultAzureCredential will automatically pick up those identities when they are available.
Coastal Harbor Credit Union is shifting its transaction systems to Microsoft Azure and the leadership has engaged you as the principal data scientist to guide their team. The group is building an automated machine learning based classification system to flag credit card fraud and the training set is very skewed with roughly one fraudulent record for every forty legitimate transactions. The head of analytics wants your recommendation on which primary evaluation metric to use given this class imbalance. Which metric should you recommend?
AUC_weighted is the correct choice.
AUC_weighted summarizes a model’s ability to discriminate between classes across all thresholds while weighting each class by its support, and that weighting makes the metric less dominated by the majority class when the dataset is highly imbalanced. This weighted ROC AUC gives a single aggregated score that still reflects performance on the rare fraud class while accounting for overall model behavior and so it is a practical primary metric for comparing classifiers in Microsoft Azure automated workflows.
normalized_root_mean_squared_error is not appropriate because it is a regression error metric and it does not apply to classification tasks.
area_under_precision_recall_curve is useful for problems that focus tightly on the positive class and for some imbalanced tasks it can be more informative than ROC AUC, but it was not the recommended primary metric in this Azure classification context where a weighted, per-class aggregate ROC measure is preferred for model comparison.
Accuracy is misleading with a 40 to 1 class imbalance because a model that always predicts the majority class will appear to perform well even though it fails to find fraud.
spearman_correlation measures rank correlation for continuous or ordinal data and it is not a standard primary evaluation metric for binary classification problems.
When a question mentions Azure Automated ML and imbalanced classes remember that you should prefer metrics that account for class support and discrimination across thresholds. Focus on metrics that are appropriate for classification and not on regression or simple accuracy. Consider AUC_weighted as the expected primary metric in these cases.
Is automated machine learning primarily intended for experienced data scientists while the guided model builder is aimed at non-experts?
The correct option is False.
The statement is false because automated machine learning is intended to lower the barrier for building models and to let non experts create useful models without deep knowledge of every modeling step while also being useful to experienced data scientists who want fast baselines, reproducible pipelines, or to scale experiments.
The guided model builder or other guided user interfaces are aimed at providing step by step assistance and sensible defaults for users who prefer a more interactive or simplified workflow, but that does not mean experienced practitioners cannot or do not use those tools for prototyping or teaching.
Automated ML typically automates tasks such as feature handling, model selection, and hyperparameter tuning, and guided builders focus on making choices easier and more transparent. Both approaches overlap in purpose and audience so the idea of a strict split between experienced and non expert users is inaccurate.
True is incorrect because it asserts a rigid separation of intended users, and in practice both automated ML and guided builders are designed to help a range of users depending on the task and the workflow.
When a question claims an absolute distinction between user groups, pause and consider whether the tools are meant to lower barriers or to accelerate workflows for multiple audiences rather than to serve only one strict group.
A data science team at Nova Analytics is assembling a modular training workflow in Azure Machine Learning and the workflow contains multiple custom components that must receive configuration values and parameters from each run. Which strategy should the team use to define these parameters so each job execution can be configured appropriately?
Place parameter definitions inside each component script so each run can supply custom values is correct.
Defining parameters inside each component script or in the component signature lets each job execution pass different values to that component without changing the component source. This approach keeps components modular and reusable and it ensures that runs can supply per component configuration at invocation time.
Embed fixed parameter values inside every component source to avoid external configuration is wrong because embedding fixed values prevents per run changes and makes components hard to reuse across different experiments. Components should accept inputs rather than hard coded values.
Declare only pipeline level parameters and apply the same values to all components without per component overrides is wrong because pipeline level parameters that apply the same value to every component do not allow component specific customization. Many workflows require different settings per component and that requires component level parameters.
Map pipeline parameters to Azure ML component inputs at runtime so runs supply values to each component is not the best choice for this question because relying solely on pipeline parameters and mappings still expects each component to declare inputs to accept values. Mapping can be useful but components need their own parameter definitions so each run can be configured at the component level.
When you study these questions focus on whether parameters must be configurable per component or only globally. If you need per run and per component flexibility prefer defining parameters at the component level so each execution can pass different values.
A data science team at Contoso is training an image classification model using pictures stored in an Azure Data Lake Storage Gen2 account. When they create a data asset that points to that storage what asset type should they pick to correctly reference the collection of image files?
The correct answer is Folder.
Folder is the right choice because a folder data asset registers a directory path in Azure Data Lake Storage Gen2 and thus references a collection of files. Image datasets are typically stored as many individual files inside a directory and a folder asset lets Azure Machine Learning mount or download the whole set for training.
Image is incorrect because Azure Machine Learning does not use an Image data asset type to reference a collection of image files. Images are handled by referencing the folder that contains them or by using a dataset that lists file paths.
Recording is incorrect because it is not a valid data asset type for pointing to files in storage and it does not represent a directory of images.
File is incorrect because a file asset points to a single file and not to a directory containing many image files. Use a file asset only when you need to register one specific file.
When a question describes many files choose a Folder asset so you register a directory. If the exam scenario specifies a single file then choose a File asset instead.
RapidShip Logistics operates out of its headquarters in Milan Italy and it has just hired Selena Torres as a data scientist. Selena needs permission to submit a script as a job to an Azure Machine Learning workspace. Which role assignment will grant Selena the permissions required to access the workspace and run jobs?
AzureML Data Scientist is the correct role assignment that will grant Selena the permissions required to access the workspace and submit and run jobs.
The AzureML Data Scientist role is designed to allow data scientists to perform data plane operations inside an Azure Machine Learning workspace. It grants the ability to submit experiments and jobs, access datasets and models, and interact with workspace resources needed for training and inference.
AzureML Compute Operator is incorrect because that role is focused on creating and managing compute targets and does not by itself grant the full workspace data plane permissions required to submit and manage experiments and jobs.
Contributor is incorrect because it is a broad management role for Azure resources and does not guarantee the specific data plane permissions inside an Azure Machine Learning workspace that are required to run jobs.
AzureML Reader is incorrect because it only provides read only access to workspace resources and therefore does not allow submitting or running jobs.
When you see questions about running jobs in a workspace think about data plane permissions and pick a role that explicitly allows submitting and managing experiments rather than a role that is read only or only manages infrastructure.
You are working in a CityTransit Python notebook and you have a Pandas dataframe named lateness_df that contains daily commuter rail lateness records with columns year month day train_no and delay_minutes. How would you compute the average of delay_minutes?
The correct option is lateness_df[‘delay_minutes’].mean().
This calls the Pandas Series method mean on the delay_minutes column and it computes the arithmetic average of the numeric values while skipping missing values by default. Using the column reference ensures you operate on the Series rather than the whole DataFrame and Pandas returns the scalar average you need.
lateness_df[‘delay_minutes’].median() is incorrect because median returns the middle value and not the arithmetic mean. Use mean when the question asks for the average and use median only when you need the central value that is robust to outliers.
Avg(lateness_df[‘delay_minutes’]) is incorrect because Avg is not a built in Pandas or Python function. The proper approach on a Series is to call the .mean() method or to pass a NumPy array to NumPy functions.
np.mean(lateness_df) is incorrect as written because calling NumPy mean on the entire DataFrame can produce unexpected results or errors if non numeric columns are present. To use NumPy you would need to call np.mean(lateness_df[‘delay_minutes’]) but the option shown does not target the specific column so it is not the right choice.
When asked for the average of a DataFrame column use the Series .mean() method. It skips missing values by default so you usually do not need extra handling unless you want a different behavior.
How can an organization evaluate fairness and reduce ethnicity related bias in a binary admissions classifier developed with Azure Machine Learning?
The correct answer is Measure and compare acceptance rates and predictive performance metrics across ethnic groups.
This approach lets the organization detect whether different ethnic groups experience systematically different outcomes or error rates and it supports evidence based decisions about mitigation. By measuring group level acceptance rates and predictive metrics such as true positive rate, false positive rate, precision, and recall you can quantify disparate impact and unequal predictive performance. Statistical tests and confidence intervals help determine whether observed differences are meaningful and not due to random variation.
Apply adversarial debiasing or reweighting during training is not the correct choice here because those are mitigation techniques rather than primary assessment steps. You should first measure and understand group level performance to identify which metrics need to be addressed before applying techniques like adversarial debiasing or reweighting as remedies.
Remove ethnicity from the dataset is also incorrect because removing the sensitive attribute does not guarantee fairness and it prevents measuring disparities by group. Models can still learn proxies for ethnicity from other features and removing the attribute removes the ability to evaluate and monitor group specific outcomes, which is essential for responsible mitigation.
When facing fairness questions prioritize options that describe active measurement across protected groups before choosing mitigation methods. Measuring differences reveals which metric to fix and prevents blind application of fixes that may not help.
In Orion Machine Learning Studio which item is not presented as an asset or shown on a screen in the interface?
The correct option is User Directory.
User Directory is not presented as an asset or shown on a screen in the Orion Machine Learning Studio interface because it is an administrative identity construct rather than a workspace resource. The Studio interface focuses on workspace assets you create and manage such as data, jobs, and endpoints so the user directory is not exposed as an asset view.
Endpoints is incorrect because endpoints are displayed and manageable in the Studio as deployed model endpoints and API integrations.
Data is incorrect because datasets and data assets appear in the Studio for browsing, preparation, and linkage to experiments.
Jobs is incorrect because job records and run history are visible in the Studio for monitoring and management of training and inference tasks.
When a question asks whether an item is shown as an asset think about whether it is a workspace resource you manage directly or an administrative setting. Items like User Directory are typically administrative and not listed as assets.
The Falcon Collective is a regional analytics consortium seeking advice on Microsoft Azure. Their lead engineer has published a pipeline and wants to use the Schedule.create method so the pipeline runs weekly. Before configuring the weekly cadence which object must the team create first?
The correct option is ScheduleRecurrence.
Azure Machine Learning scheduling requires a recurrence object to define cadence and ScheduleRecurrence is the class used to specify weekly or other recurring settings for a pipeline run.
When you call Schedule.create you pass the recurrence definition so you must create the ScheduleRecurrence instance first to set frequency, interval, and start times before creating the schedule resource.
The option DataReference is incorrect because it refers to pointers to data in storage for experiments and it does not control scheduling cadence.
The option PipelineParameter is incorrect because it represents runtime inputs to a pipeline and it does not define when the pipeline should run.
The option Schedule is incorrect because it is the schedule resource that you create with the API and it depends on a recurrence object, so the recurrence must exist first.
The option Datastore is incorrect because it holds connection information for storage and is unrelated to the timing or recurrence of pipeline executions.
When a question asks about scheduling in Azure Machine Learning think about which object defines the frequency and times first because the recurrence object is usually created before the schedule itself.
What must a data scientist have configured to connect from a local Python environment to a CloudWorks machine learning workspace using the Python SDK?
A local workspace configuration file and invoking Workspace.from_config in the Python SDK is the correct option.
A local workspace configuration file stores the workspace identification and connection details that the SDK needs and Workspace.from_config is the Python SDK helper that reads that file and returns a configured Workspace object you can use from your local environment. This approach avoids hard coding credentials and lets the SDK locate the workspace by name and project settings so your local code can interact with the cloud workspace.
A Compute Engine virtual machine with CPU or GPU resources is incorrect because you do not need to run on a cloud VM to connect the Python SDK to a workspace. A VM may provide compute capacity but it is not required for establishing the SDK connection.
A Google Cloud service account with application default credentials is incorrect in this context because the question specifies using the workspace configuration and the SDK helper. Application default credentials are used by some Google Cloud client libraries but they are not the required mechanism for Workspace.from_config.
An App Engine deployment with environment variables set for the workspace is incorrect because deploying to App Engine is not necessary to connect from a local Python environment. Environment variables can work for configuration in some workflows but the standard local method is the configuration file plus Workspace.from_config.
When a question asks how to connect from a local SDK look for answers that mention a local configuration file and the SDK helper such as Workspace.from_config because those are the standard local development mechanisms.
A data engineer at Meridian Analytics is assembling a pipeline in Azure Machine Learning Studio Designer and they need to remove extreme values from a single feature column in a dataset. Which Designer component should they choose?
Clip Outliers is the correct choice.
The Clip Outliers component is specifically designed to detect and remove or cap extreme values in a single feature column so that those values do not unduly influence model training. This component provides options to set thresholds or use statistical rules to clip values that fall outside an expected range.
Impute Missing Values is incorrect because it is used to fill in missing or null entries in a dataset and it does not remove or clip extreme values.
Scale Features is incorrect because it rescales numeric features to a common range or variance and it does not explicitly remove outliers by clipping them.
Normalize Data is incorrect because it adjusts vectors to a common norm or range and it is not a mechanism for removing or capping extreme values.
When you see tasks that mention removing or clipping extreme values look for components that explicitly mention outliers or clipping rather than imputation or scaling operations.
Which feature scaling technique transforms continuous variables so they have a mean of zero and a standard deviation of one?
The correct answer is Z score standardization. It rescales continuous features so they have mean zero and standard deviation one.
Z score standardization subtracts each feature’s mean and divides by its standard deviation. The result is a transformed feature with mean close to zero and standard deviation one and this is what the question specifically describes.
MinMax normalization rescales features to a fixed range such as zero to one and it does not enforce mean zero or unit variance.
Robust scaling with median and interquartile range centers using the median and scales by the IQR so it is resistant to outliers but it does not guarantee a standard deviation of one.
Log transformation applies a nonlinear change to reduce skewness and compress large values and it does not by itself produce features with mean zero and standard deviation one unless additional scaling is applied.
When a question asks for mean zero and standard deviation one look for terms like z score or standardization rather than range based methods or robust transforms.
The Harbor Chronicle is a regional news startup that has engaged you to streamline its model training workflows and the lead engineer Alex Rivera configured Azure Machine Learning Hyperdrive with a parameter search defined as param_sampling = RandomParameterSampling({ “learning_rate”: normal(12,4), “dropout_prob”: uniform(0.02,0.08), “batch_size”: choice(32,64,128,256), “hidden_layers”: choice(range(2,6)) }) What statements about how Hyperdrive will sample these hyperparameters are correct?
The correct answer is Random values for the learning_rate parameter will be sampled from a normal distribution with a mean of 12 and a standard deviation of 4.
Hyperdrive’s Random values for the learning_rate parameter will be sampled from a normal distribution with a mean of 12 and a standard deviation of 4 follows directly from the normal(12,4) specification. The normal function defines a distribution with mean 12 and standard deviation 4 so samples for the learning_rate are drawn continuously around that mean.
Defining sampling this way will exhaustively evaluate every combination of the parameters is incorrect because RandomParameterSampling uses independent random draws and does not enumerate all combinations. An exhaustive evaluation of all combinations would be performed by a grid search approach rather than random sampling.
The dropout_prob parameter will only ever be either 0.02 or 0.08 is incorrect because uniform(0.02,0.08) specifies a continuous uniform distribution between 0.02 and 0.08. Values can be any number in that range and are not limited to the two endpoints.
The hidden_layers parameter will draw values from a normal distribution with a mean of 3 and a standard deviation of 5 is incorrect because choice(range(2,6)) indicates discrete choices of 2, 3, 4, or 5. It is a discrete selection from that set and not a normal distribution.
When you see sampling functions like normal, uniform, or choice read them literally to know whether values are continuous or discrete. Also remember that RandomParameterSampling picks random points and does not perform an exhaustive grid search.
Horizon Materials a UK chemical manufacturer headquartered in Manchester operates facilities across several countries and employs many technicians. For a computer vision project you and a Horizon technician must detect and extract the precise outlines of separate items inside images using Azure AutoML. Which computer vision model in Azure AutoML should you select to achieve this outcome?
Instance segmentation is correct because it produces pixel level masks for each object instance and so it can detect and extract the precise outlines of separate items inside images.
Instance segmentation gives a separate mask for every detected object so it captures the exact shape of each item even when objects overlap and that is why it is suitable for technician workflows that need precise edges for measurement or inspection.
Multi-label image classification is incorrect because that approach assigns multiple class labels to an entire image and it does not locate objects or provide outlines for individual items.
Object detection is incorrect because it returns bounding boxes and class labels and not pixel precise masks so it cannot provide the exact outlines required.
Multi-class image classification is incorrect because it assigns a single class to the whole image and it does not detect individual objects or their shapes.
Read the task description for requests for pixel or mask level output and match those phrases to segmentation models rather than to detection or classification models.
A data science group at Contoso Analytics wants to connect Azure Machine Learning to an automated build and release workflow using Azure DevOps so that training runs start automatically when code is pushed to the repository. Which method should they implement?
The correct option is Set up an Azure DevOps pipeline with a commit trigger that invokes Azure Machine Learning training runs.
This choice uses an automated CI pipeline that triggers on repository commits and runs tasks to start training with Azure Machine Learning. By using a Azure DevOps pipeline you can configure commit triggers and include steps that invoke the Azure ML CLI, SDK, or REST API so training starts automatically when code is pushed.
Use Azure Event Grid to listen for repository push events and start training via webhooks is incorrect because Azure DevOps pipelines provide native commit triggers and built in tasks for invoking Azure Machine Learning. Relying on Event Grid and custom webhooks adds unnecessary complexity and is not the standard integration path for an Azure DevOps build and release workflow.
Manually start training jobs from the Azure Machine Learning studio after each code change is incorrect because it does not automate the process and requires human intervention. The question asks for an automated build and release workflow that begins training on code pushes so manual starts do not meet that requirement.
Configure recurring scheduled runs in Azure Machine Learning that run regardless of repository changes is incorrect because scheduled runs are time based and do not respond to repository pushes. Scheduled runs will execute whether or not code has changed so they do not provide trigger based automation tied to commits.
When a question asks for automation on code pushes look for answers that mention commit triggers or CI pipelines and integration with the repository host rather than manual or time based solutions.
A data science group at BrightAnalytics has deployed a model as a real time service on Azure Kubernetes Service and they use the Azure ML SDK to examine the deployment. The following Python code snippet is used to interact with an AKS hosted web service python from azureml.core.webservice import AksWebservice service = AksWebservice(name = ‘image-classifier-v2’, workspace = ws) print(service.state) What does this code do when investigating a deployed Azure Machine Learning service?
The correct option is Prints the current state of the AKS deployed web service.
The code creates a reference to the AKS hosted web service by name in the given workspace and then prints the value of the service’s state property to the console. The state property reflects the current deployment status such as Healthy, NotReady, or Updating and printing it simply displays that status.
Retrieves recent service logs from the container to diagnose errors is incorrect because the snippet does not call any log retrieval method. To get container logs you would call the webservice logging method such as get_logs on the service object.
Performs an internal error inspection on the AksWebservice object for exceptions is incorrect because printing service.state only reads a status property and does not perform exception analysis or run diagnostic checks on the object.
Queries historical availability metrics for the service in the workspace is incorrect because the state property is a current status indicator and it does not query historical telemetry. Historical availability requires Azure Monitor or metrics APIs rather than the service.state property.
When you see code that prints service.state expect a simple current status check. Use get_logs() for container logs and use Azure Monitor for historical metrics.
Which classification outcome describes an instance that is truly positive and is predicted as positive by the model?
The correct answer is True Positive.
A True Positive describes an instance whose actual label is positive and whose predicted label from the model is also positive. This outcome means the model correctly identified a positive case and it appears in the confusion matrix cell for actual positive and predicted positive. The count of True Positive values is used to compute common metrics such as recall and precision.
False Negative is incorrect because that outcome means the instance is actually positive but the model predicted negative. That is the opposite of a true positive and it reduces recall.
Precision is incorrect because precision is a metric rather than an individual classification outcome. Precision measures the proportion of predicted positives that are actually positive and it is calculated using true positives and false positives.
When answering outcome questions focus on the relation between the actual label and the model prediction and remember that a True Positive requires both to be positive.
A data scientist at Contoso Data Labs is using the Azure Machine Learning Python SDK v2 to run automated machine learning for a regression problem, and the dataset contains missing values and categorical columns with a small set of categories. Which enum from the automl package should be used to explicitly manage automatic imputation and categorical encoding during the AutoML run?
The correct option is FeaturizationMode.
FeaturizationMode is the enum in the automl package that controls how automatic featurization is applied during an AutoML run. It allows you to explicitly enable or disable automatic imputation and categorical encoding and to select the automatic strategies that handle missing values and low cardinality categorical features.
Using FeaturizationMode you can influence whether the AutoML pipeline will perform imputation for missing data and apply appropriate encoding for categorical columns that contain a small set of categories. This is the setting you would change when you need explicit control over preprocessing behavior for a regression problem with missing values and categorical variables.
RegressionModels is incorrect because that enum lists or configures model families and algorithms and it does not control preprocessing steps such as imputation or categorical encoding.
TaskType is incorrect because that enum specifies the overall AutoML task like regression or classification and it does not manage featurization or preprocessing details.
RegressionPrimaryMetrics is incorrect because that enum selects evaluation metrics used to score models in a regression run and it has no role in controlling automatic imputation or categorical encoding.
When a question focuses on preprocessing or handling missing values look for options that mention featurization. The FeaturizationMode setting is the one that controls imputation and categorical encoding in AutoML.
A data scientist at Nimbus Analytics needs to separate a dataset into two distinct parts inside the Contoso Machine Learning Studio workspace for model training and validation. Which module should they use to perform this split?
Split Data is the correct option for creating separate training and validation datasets inside the Contoso Machine Learning Studio workspace.
The Split Data module is specifically designed to partition a dataset into two or more outputs using a fraction, stratified sampling, or custom filtering. It provides options to control the split ratio and a random seed so that you can reproduce the same training and validation sets across experiments. This makes it the proper choice when you need distinct datasets for model training and validation within Azure Machine Learning Studio.
Group Records into Buckets is incorrect because that operation groups or bins records for aggregation or analysis and it does not produce separate training and validation datasets for model evaluation.
Assign to Clusters is incorrect because that action assigns records to cluster labels after clustering and it is not intended to split a dataset into training and validation parts.
BigQuery is incorrect because it is a Google Cloud data warehouse service and not a module inside Azure Machine Learning Studio, so it is not the tool you would use within the Contoso workspace to split data for model training and validation.
When preparing data in Azure Machine Learning Studio use the Split Data module and set a fixed random seed if you need reproducible training and validation splits.
Scenario: Meridian Data is a regional logistics analytics company founded by Clara Reyes and it offers route optimization fleet monitoring and delivery analytics. To modernize their analytics stack Clara adopted Microsoft Azure and hired you to consult on model evaluation practices for a regression project. The analytics team is discussing Mean Squared Error as an evaluation metric. Which of the following statements about Mean Squared Error is correct? (Choose 2)
The correct answers are An MSE of zero indicates a perfect fit and MSE values are always greater than or equal to zero.
An MSE of zero indicates a perfect fit because every prediction matches the ground truth exactly so each squared error is zero and the mean of those zeros is zero.
MSE values are always greater than or equal to zero because each error is squared before averaging and squared values cannot be negative, so the average of non negative numbers is also non negative.
MSE can be negative for models that systematically underpredict is incorrect because underprediction may produce negative residuals but squaring those residuals makes them positive and prevents a negative mean.
A higher MSE denotes a better performing model is incorrect because a higher MSE means larger average squared errors and thus worse predictive accuracy, so lower MSE is the desired outcome.
When judging regression models focus on the relative magnitude of MSE and prefer the model with the lower MSE, and also inspect residuals to reveal systematic bias that a single metric can hide.
Scenario: Cloudbridge Recruiting is a senior talent firm led by CEO Mara Finch and based in Brooklyn New York. The technology team is preparing to publish a new credit risk model as a batch endpoint and they need guidance on the proper way to load the model inside their batch scoring script. Which method should the scoring script use to load the model before processing mini batches?
The correct option is init.
init is executed once when the scoring process starts so it is the appropriate place to load the model into a global or module level variable before processing mini batches.
Placing the model load in init avoids repeated deserialization and keeps per mini batch inference fast and resource efficient.
run is called for each scoring request or for each mini batch so loading the model there would cause repeated loads and poor performance.
azureml_main was part of older Azure Machine Learning patterns and is not the standard initializer for modern scoring scripts so it is not the correct choice for a deployment that expects an init initializer.
main is a generic function name and is not the expected one time initializer for Azure ML scoring scripts so it does not ensure the model is loaded only once before batch processing.
When you must choose where to load a model look for the function that runs once per deployed process and not the one that runs per request. The name init commonly indicates that one time initializer.
How do regression models primarily differ from classification models in the type of output they produce?
Classification assigns discrete category labels while regression forecasts continuous numeric values is correct.
This option is correct because classification models map inputs to a finite set of discrete classes and regression models predict continuous numeric targets on a real valued scale.
In practice a classification example is predicting whether an email is spam or not spam and a regression example is predicting a house price or a temperature value.
Regression predicts category labels is incorrect because it reverses the roles of the two problem types. The statement claims that regression produces category labels when in fact regression predicts continuous values and classification produces discrete labels.
Azure Machine Learning is incorrect because it names a cloud machine learning platform rather than describing what differentiates regression from classification. The question asks about model types and not about a specific service.
When you see these questions focus on whether the target variable is discrete or continuous. If the target is discrete pick classification and if it is continuous pick regression.
Which query language does Contoso Data Explorer use to express its data retrieval and analytics statements?
The correct option is Kusto Query Language.
Kusto Query Language is the native query language for Azure Data Explorer and therefore for Contoso Data Explorer. It was designed for fast ad hoc exploration and time series analytics and it provides a rich set of operators for filtering, summarization, and joins which makes it well suited to data retrieval and analytics workloads.
BigQuery is a Google Cloud product and not the query language used by Contoso Data Explorer. It is a separate data warehouse service that uses its own SQL dialects.
Structured Query Language refers to standard SQL used by many relational systems and it is not the native language for Azure Data Explorer. Azure Data Explorer uses Kusto Query Language rather than standard SQL as its primary query language.
Python SDK is a client library and programming interface that can submit queries and process results but it is not a query language. The Python SDK can be used to run queries written in Kusto Query Language but it does not replace the language itself.
When a question asks for the query language map the product name to its native query language and remember that SDKs and client libraries are interfaces rather than languages.
Crescent Robotics operates from Lakeside Park in Chicago and it is expanding quickly which has created new IT priorities that the lead engineer has asked you to address. A group of interns have minimal experience with Azure Machine Learning and they have requested a concise description. Which of the following key points should you explain to them?
A cloud based platform for running and operationalizing machine learning solutions at scale is the correct option.
Azure Machine Learning is a managed cloud service that helps teams prepare data, run experiments, train models, deploy models to production, and monitor models in operation. The service provides hosted compute, a web based studio, ML pipelines, a model registry, and integrations with popular frameworks to support production scale workflows.
A Windows desktop application that lets you build machine learning models with a drag and drop interface for virtual machines is incorrect because Azure Machine Learning is not a Windows desktop application and it is not limited to virtual machines. The Azure service is accessed through the cloud and a web based studio rather than a local drag and drop desktop tool.
Vertex AI is incorrect because that name refers to Google Clouds managed machine learning platform and not Microsofts Azure offering. Both are cloud ML platforms but they belong to different cloud providers.
A Python library meant to replace Scikit Learn PyTorch and TensorFlow is incorrect because Azure Machine Learning is not a single library and it does not replace those frameworks. Instead it supports Scikit Learn, PyTorch, TensorFlow, and other libraries and provides services for training, deployment, and MLOps.
When you see questions about managed machine learning services look for choices that mention cloud based, operationalizing, and scaling as these words usually point to end to end, production oriented platforms.
Dr. Elena Voss leads a data science group at Nova Dynamics which was founded by Marcus Lin and they are using Microsoft Azure Machine Learning automated experiments to pick the model with the highest AUC_weighted score. Which AutoMLConfig parameter should they configure to optimize for that metric?
The correct option is primary_metric=’AUC_weighted’.
In Azure Machine Learning Automated ML you set the metric that the service should optimize by using the primary_metric=’AUC_weighted’ parameter in the AutoMLConfig. This tells the automated search to rank and select models based on the weighted area under the ROC curve.
AUC_weighted measures the weighted average of class wise AUC and is useful when you want a single summary metric for multiclass or imbalanced classification. Setting primary_metric aligns the AutoML optimization objective with that metric.
task=’AUC_weighted’ is incorrect because the task parameter specifies the problem type such as ‘classification’ or ‘regression’ and it is not used to choose the evaluation metric.
compute_target=’AUC_weighted’ is incorrect because compute_target designates the compute resource where the experiment runs and it cannot be a metric name.
label_column_name=’AUC_weighted’ is incorrect because label_column_name should be the name of the target column in your dataset and it does not control which metric AutoML optimizes.
When a question asks which AutoMLConfig parameter controls the optimization objective look for the parameter that mentions metric and remember to set primary_metric to the metric you want AutoML to maximize.
A retail banking startup plans to deploy a model for immediate transaction decisions and the engineering team must choose between an Azure online endpoint and batch scoring. Which situation most strongly supports deploying the model to an Azure online endpoint?
Real time credit card fraud scoring that requires millisecond response times is correct because the use case demands immediate, per transaction decisions and an online endpoint supports low latency synchronous inference suitable for that requirement.
An online endpoint is designed for real time scoring and it can return predictions within milliseconds when configured with the right compute and autoscaling settings, which makes it the right choice for fraud detection that must act on individual transactions as they occur.
Scheduled overnight scoring of a 25 TB transaction archive is incorrect because that scenario is a large volume, offline job that is best handled by batch scoring, which is optimized for throughput and cost efficiency rather than millisecond latency.
Hosting the model on Azure Kubernetes Service for gradual canary deployments is incorrect as stated because this option describes an infrastructure and deployment strategy rather than a scoring mode, and it does not directly address the need for millisecond real time responses. Azure Kubernetes Service can host real time endpoints but the question contrasts online endpoints with batch scoring.
Producing monthly sales performance analyses for stakeholder review is incorrect because monthly analytical reports are not latency sensitive and they are better served by batch processing or analytics pipelines that process aggregated data on a schedule.
When you see a choice between online endpoints and batch scoring look for mentions of per transaction or milliseconds to favor online endpoints and look for large archives or scheduled jobs to favor batch scoring.
Which of the following methods can be used to transfer data into Azure Blob Storage for use in model training? (Choose 3)
The correct options are Azure Storage Explorer, AzCopy and Python script.
The Azure Storage Explorer application provides a graphical interface to browse storage accounts and to upload or download blobs. It is useful for manual or ad hoc transfers and for verifying container structure and access controls.
The AzCopy tool is a command line utility that is optimized for high throughput and parallel transfers. It is well suited for large scale or recurring bulk uploads and it supports resume and high performance options that speed data movement into Blob Storage.
The Python script approach uses the Azure Storage Blob client library so you can programmatically upload data from preprocessing steps or integrate uploads into training pipelines. Scripts are ideal for automation and for custom data transformations before sending files to Blob Storage.
Bulk Insert SQL Query is incorrect because bulk insert operations target database tables and not Blob Storage. A bulk insert writes data into a relational database and does not directly upload files as blobs.
When deciding which method to use prefer AzCopy for large and fast transfers, use Azure Storage Explorer for manual or exploratory uploads, and choose Python scripts when you need automation or custom processing before upload.
EdgeWorks Analytics uses Azure Machine Learning and teams can interact with the service using purpose built graphical tools or by using programmatic interfaces. Which approaches allow engineers to manage assets inside an Azure Machine Learning workspace? (Choose 2)
The correct options are Azure Designer and Application Programming Interface.
Azure Designer is the built in visual, low code authoring environment in Azure Machine Learning that lets engineers build and manage pipelines, components, datasets, and experiments inside a workspace. It is the purpose built graphical tool referenced in the question.
Application Programming Interface refers to the Azure Machine Learning SDKs and REST APIs that let engineers programmatically create, read, update, and delete workspace assets such as models, datasets, endpoints, and pipelines. This is the programmatic approach mentioned in the question.
Azure portal is the general Azure management console for subscriptions and resources and it is not the dedicated graphical authoring environment for Azure Machine Learning workspace assets.
Azure Machine Learning Studio is an ambiguous term because it can refer to the older classic Studio that was retired or to the modern web UI, and exam items prefer the specific Designer component or the APIs. Because of that ambiguity and the deprecation of the classic Studio it is not the intended answer on newer exams.
Azure Application Gateway is a web traffic load balancer and it does not provide features to manage Azure Machine Learning workspace assets.
Azure Connect is not a tool for managing Azure Machine Learning workspace assets and it does not provide the graphical or programmatic interfaces described in the question.
When a question contrasts graphical and programmatic approaches look for the product name that implies visual authoring and for mentions of SDK or REST APIs. The visual tool will often be called Designer and the programmatic option will be the API.
How can you confirm that a predictive model does not produce biased results across different racial groups?
Evaluate fairness and accuracy metrics across demographic groups is correct.
Evaluate fairness and accuracy metrics across demographic groups means computing and comparing performance and fairness measures for each racial group so you can detect disparate impact or unequal error rates. You should look at accuracy, false positive and false negative rates, calibration and group specific metrics and then assess whether observed differences are statistically meaningful and acceptable for your use case.
This evaluation should include checks for small sample sizes and intersectional subgroups so you do not miss harms that affect a subset of the population. If you find disparities you can apply mitigation techniques such as reweighting, resampling, fairness constrained training or post processing and then re evaluate the metrics to confirm improvement.
Vertex AI Model Evaluation is incorrect because a product or tool by itself does not confirm absence of bias unless you actually measure and compare fairness metrics across groups. The tool can help but the correct approach is to perform explicit fairness and accuracy evaluations.
Omit the race attribute from the training data is incorrect because removing the sensitive attribute does not prevent the model from learning proxies for race and it also prevents you from measuring whether outcomes differ by race. You need the attribute or a reliable proxy to evaluate group level performance and to guide mitigation.
Train the model using data from a single racial group is incorrect because training on a single group will not generalize and will likely produce highly biased outcomes for other groups. That approach increases discrimination rather than preventing it.
When an exam question asks about confirming lack of bias choose answers that mention measuring and comparing metrics across protected groups and consider statistical significance and subgroup sizes.
Orion Dynamics is an aerospace analytics firm that has adopted Azure Machine Learning to train a convolutional neural network for image classification. A data scientist has a training script that requires CUDA capable GPUs and needs to submit the experiment within the Azure Machine Learning workspace. Available compute resources include a corporate laptop that blocks additional software installation, a compute instance named dev-workstation with 2 vCPUs and 10 GB of memory, an Azure Machine Learning compute target named cpu-pool with ten CPU nodes, and an Azure Machine Learning compute target named gpu-pool with five nodes that provide CPUs and NVIDIA GPUs. Which compute resource should the data scientist choose to execute the training script to minimize total model training time?
gpu-pool compute target is the correct choice to minimize total model training time.
The training script requires CUDA capable GPUs and the gpu-pool compute target provides nodes with NVIDIA GPUs so it can run CUDA accelerated training. The gpu nodes also allow for parallel and distributed training across multiple nodes which substantially reduces wall clock time for convolutional neural network training compared with CPU only resources.
dev-workstation compute instance is not suitable because it has only 2 vCPUs and 10 GB of memory and it does not provide the necessary CUDA capable GPUs for efficient CNN training.
cpu-pool compute target is not appropriate because it consists of CPU only nodes and cannot use CUDA or NVIDIA GPU acceleration, so training a CNN there would be much slower.
corporate laptop is not a viable option because it blocks additional software installation so you cannot install the CUDA drivers and runtime that the training script requires for GPU acceleration.
When a question states a script requires CUDA capable GPUs choose a managed compute target that explicitly lists NVIDIA GPUs and supports distributed training and managed drivers to reduce wall clock time.
A retail analytics startup named Meridian Analytics has deployed a trained model as a service on a managed Kubernetes cluster of their cloud machine learning platform. Production client applications will not include the platform SDK. How will those client applications typically invoke the deployed model service?
The correct answer is REST interface.
Managed model endpoints on a Kubernetes based serving platform are typically exposed as HTTP endpoints, and a REST interface is the most universally accessible way to call them from production clients that do not include the vendor SDK. Plain HTTPS requests work from almost any language and environment without additional libraries.
gRPC interface is not the best choice here because gRPC relies on HTTP2 and generated client stubs and it is less convenient for simple clients that avoid platform SDKs and for environments that do not natively support gRPC.
SOAP interface is incorrect because SOAP is an older XML based protocol and it is rarely used for modern cloud model serving. Managed ML services do not typically offer SOAP endpoints for model inference.
JSON interface is incorrect because JSON is a data format and not an invocation interface. JSON is commonly used as the request and response payload for a REST interface but choosing JSON as the interface misunderstands how clients call the deployed service.
When clients will not include an SDK choose the interface that works with plain HTTP and standard payloads. REST endpoints with JSON bodies are the most portable option to look for on exam questions.
Which Azure Machine Learning run logging methods should be used respectively to log a scalar observation, a matplotlib figure, and a dataframe or dictionary?
run.log then run.log_image then run.log_table is correct.
The reason is that run.log is used for scalar metrics and single numeric observations so it is the right choice for logging a single value. run.log_image is designed to accept matplotlib figures or image files and store them with the run for later visualization. run.log_table is intended for tabular payloads such as pandas dataframes or dictionaries and it captures rows and columns for inspection.
run.log_table then run.log_image then run.log is incorrect because it places tabular logging first and the scalar logger last. The scalar metric should be recorded with run.log rather than using the table method.
run.log then run.log_table then run.log_image is incorrect because it swaps the image and table steps. The figure should be logged with run.log_image and the dataframe or dictionary should be logged with run.log_table.
run.log_row then run.log_figure then run.log_table is incorrect because those are not the standard SDK method names for this common workflow. The documented methods to use are run.log for scalars and run.log_image for matplotlib figures and the option mixes in nonstandard names.
When you read logging questions match the method name to the data type. Use run.log for single numeric values, run.log_image for figures, and run.log_table for tabular data.
Convolutional neural networks are a standard choice for image understanding at a fictional company called PixelWorks which builds visual recognition systems. These architectures extract spatial features through specialized layers and then pass those features into a dense network for final prediction. Which of the following are valid layer types in a convolutional neural network? (Choose 5)
Flattening layers, Dropout layers, Convolution layers, Pooling layers, and Fully connected layers are correct.
Convolution layers form the core of a CNN because they apply learnable filters to extract spatial features from images. Pooling layers reduce the spatial resolution of feature maps and provide robustness to small translations. Flattening layers reshape multi dimensional feature maps into a one dimensional vector so that the outputs can be passed into dense layers. Fully connected layers use those flattened features to perform the final classification or regression. Dropout layers are commonly used as a regularization technique between layers to reduce overfitting by randomly disabling units during training.
Normalization layers is marked incorrect here because the term can be ambiguous in exam wording. Normalization is often done as preprocessing and some frameworks also provide specific normalization layers such as batch normalization, but the question is focusing on the canonical architectural building blocks for spatial feature extraction and classification rather than ambiguous preprocessing steps.
Focus on the role each layer plays in the network when you answer these questions and watch for ambiguous terms like normalization which can mean preprocessing or a specific framework layer.
Rafferty’s Eats is a regional quick service chain that competes with Griddle King and they have hired you to advise on Azure data science projects, and you are leading a meeting on model training. The team built a regression model using scikit-learn and when tested on unseen data it yielded an R-squared score of 0.93. What does that metric indicate about the model’s performance?
The model explains about 93 percent of the variance in the target variable.
R-squared, often written as R², quantifies the proportion of the target variable’s variability that the model can explain using the input features. A value of 0.93 means the model explains about 93 percent of the variance and leaves about 7 percent unexplained by the predictors.
R-squared does not directly tell you the average size of prediction errors or whether predictions are biased. It is a goodness of fit measure and higher values generally indicate a better fit to the data, but you should also check residuals and other error metrics to understand prediction accuracy and bias.
On average predictions exceed actual values by 0.93 units is incorrect because that statement describes mean error or bias, not the proportion of variance explained. A mean error of 0.93 units would be reported as an average difference in the target units rather than as R-squared.
The model achieves 93 percent accuracy is incorrect because accuracy is a classification metric and does not apply to regression models. R-squared is not the percentage of correct predictions and cannot be interpreted as classification accuracy.
Inputs with larger values always produce larger outputs is incorrect because R-squared does not imply a monotonic or positive relationship between inputs and outputs. A high R-squared can coexist with negative slopes or complex nonlinear relationships that still explain variance.
When you see R-squared on a regression question remember it measures the proportion of variance explained and not the average prediction error or classification accuracy.
Maya Chen at Meridian Analytics is building a new Azure Machine Learning pipeline that uses structured tables which require frequent access during model training and validation. Using Azure ML SDK v2 which data asset type should she register to provide efficient access and processing?
The correct option is mltable.
mltable is the native Azure Machine Learning SDK v2 data asset type for tabular data and it is designed to provide efficient access and processing for structured tables during training and validation.
It captures schema and can reference partitioned files such as Parquet to enable fast columnar reads. It also supports lazy loading and streaming so training jobs can read data efficiently without requiring entire datasets to be loaded into memory.
FileDataset represents file based datasets and it is not the v2 tabular asset type so it is not optimal for structured tables or for the tabular read optimizations that mltable provides.
uri_folder points to a folder of files and it is useful for unstructured or file artifacts. It does not provide the tabular schema, metadata, or columnar performance features that make mltable suitable for frequent table access during training.
TabularDataset was used in earlier versions of the SDK and it is not the v2 data asset for tabular data. It is therefore considered legacy and is less likely to be the correct choice for questions that explicitly reference Azure ML SDK v2.
Read the SDK version in the question and pick the data asset that matches it. For Azure ML SDK v2 prefer mltable when the data is structured and needs efficient tabular access.
Maya Reyes is the principal engineer at the cloud media startup Nebula Systems and she is leading the rollout of Microsoft Azure for the analytics group. She needs to register an Azure Blob container as a datastore for Azure Machine Learning using the Azure ML SDK v2. Which class or method should she use to register the Blob storage as a datastore?
AzureBlobDatastore is the correct option.
The AzureBlobDatastore class is the Azure Machine Learning SDK v2 datastore entity that represents an Azure Blob Storage container. You instantiate this datastore entity with the container and authentication details and then register it with the MLClient datastores API so the workspace can access the blob container for datasets and jobs.
AzureFileDatastore is intended for Azure File shares and not for Blob storage, so it is not the right choice for registering a blob container.
ml_client.datastores.create_or_update is not the datastore entity class that represents a blob container. The question asks for the class or resource used to represent and register blob storage, and that is the datastore entity rather than this method name.
AzureDataLakeGen2Datastore targets Azure Data Lake Storage Gen2 and is not the correct type for a plain Azure Blob Storage container, so it does not apply when registering a blob container.
When a question asks for a class name pick the datastore entity that matches the storage type, and focus on the service name such as AzureBlobDatastore rather than on client helper method names.
How do you run an Azure Machine Learning training job on a scalable compute cluster using a designated Python environment while taking input from an Azure Blob storage data asset?
Register a custom Python environment and target an Azure ML compute cluster while referencing the Azure Blob data asset is correct.
Registering a custom Python environment captures the exact package versions and system dependencies so the training run is reproducible and portable. Targeting an Azure ML compute cluster gives you a scalable pool of nodes to run distributed or larger training jobs. Referencing the Azure Blob storage as a data asset lets Azure ML manage access and mounting or downloading of the data in a way that integrates with jobs and keeps the run configuration declarative.
Use a compute instance with the platform default Python environment and access Blob storage directly from the script is incorrect because a compute instance is a single node and not designed for scalable cluster training. The platform default environment may not contain the required libraries and it does not give you the reproducibility and isolation that a registered environment provides.
Run on Azure Batch with a custom VM image and copy Blob data into the job image before execution is incorrect because copying data into VM images is inefficient and hard to manage at scale. Azure Batch is a separate orchestration service and it does not provide the same native integration with Azure Machine Learning environments and data assets that you get when using AML compute clusters and registered data assets.
Look for answers that mention managed environments, compute clusters, and registered data assets because those options align with Azure Machine Learning practices for reproducible and scalable training.
SwiftParcel Logistics hired Rachel Morgan as a data scientist at its new headquarters in Valencia Spain and Rachel trains a regression model and she wants to record the root mean squared error within the MLflow experiment run for later monitoring and comparison. Which function should she call to log the RMSE?
The correct option is mlflow.log_metric().
mlflow.log_metric() is the MLflow Python API call for recording numeric evaluation results such as root mean squared error within a specific experiment run. You call it with a metric name and a numeric value and you can optionally include a step or timestamp when you record the value. This function stores the metric so it can be displayed, compared, and monitored across runs.
mlflow.log_artifact() is incorrect because it is used to upload files and other artifacts to the run rather than to record a scalar metric value.
mlflow.autolog() is incorrect for this specific question because it enables automatic logging of model training details and metrics in supported libraries instead of being the explicit function you call to log a metric like RMSE.
mlflow.log_param() is incorrect because it records parameters or hyperparameters as key value pairs and not performance metrics.
When you need to record a single numeric evaluation such as RMSE remember to use mlflow.log_metric() and use mlflow.log_param() only for hyperparameters and mlflow.log_artifact() only for files.
Scenario: Meridian Analytics is a private firm controlled by Priya Rao and it reports an estimated market capitalization near forty-five million dollars. The business formed after the Meridian Foundation and Priya serves as chief executive officer and board chair. She asked for advice because her IT staff plans to adopt Microsoft Azure Machine Learning for upcoming data projects. During a group workshop you are explaining the notebook file types that Databricks accepts. Which file extension does Databricks support for notebook export and import?
The correct answer is DBC.
DBC is the Databricks archive format used to package notebooks, folders, and workspace metadata for export and import. You can export workspaces or collections of notebooks as a DBC archive from the Databricks UI or the CLI and then import the same archive into another workspace to preserve structure and metadata.
.spark is not a recognized Databricks notebook export extension and it does not represent the archive format used by Databricks. It appears to be a generic reference to Spark rather than a supported import or export file type.
Cloud Dataproc is a Google Cloud managed Spark and Hadoop service and it is not a file extension. It is unrelated to Databricks notebook export and import so it cannot be the correct file type.
.dbr is not the Databricks archive extension and is therefore incorrect. The proper Databricks archive format is DBC, which is commonly presented as files with a .dbc extension when exported.
When a question asks about file types focus on the exact extension and the specific product that uses it. For Databricks remember the archive format is DBC rather than general service names or similar sounding extensions.
Scenario: Arcadia Robotics, founded by Elena Park, has expanded into a leading industrial robotics company by integrating Azure Machine Learning into its projects. For a new model training workflow Elena needs to register structured data that is distributed across many text files so her team can access it with the fewest steps possible. Which type of data asset should she register to accomplish this?
The correct answer is An MLTable data asset that references the collection of text files and defines a tabular schema.
An MLTable data asset that references the collection of text files and defines a tabular schema is the right choice because it lets you register many related text files as a single logical, tabular dataset for training. This approach supports defining a schema and file patterns so the team can load the distributed structured data with minimal steps in experiments and pipelines.
A single CSV file hosted at a public HTTPS address is incorrect because that option represents a single file and not a distributed collection of many text files, so it would not match the requirement to register data spread across many files.
A folder of image files meant for computer vision experiments is incorrect because image folders are intended for unstructured image data and not for registering structured tabular data from text files.
A single large video file stored in blob storage is incorrect because a single video blob is not a set of structured text files and it does not provide a tabular schema for model training.
When a question asks about registering many related files as a table think of using an MLTable data asset because it provides a schema and unified access for experiments.
A fintech startup called NorthBridge is training a loan approval model and wants to make sure the model does not produce unfair outcomes across racial groups. What validation steps should the team take to confirm the model treats different races fairly?
Evaluate fairness and performance metrics for each racial group and apply mitigation techniques when disparities appear is correct.
This approach is correct because fairness requires first measuring model behaviour across groups and then taking targeted action when gaps appear. Evaluating per group performance reveals differences in metrics such as false positive and false negative rates and calibration, and applying mitigation methods like reweighting, threshold adjustment, or fairness-aware training can reduce those disparities. This process also enables ongoing monitoring and documentation so the team can detect regressions and ensure consistent treatment over time.
Train multiple models each on data from only one racial group is incorrect because training separate models for each group does not guarantee fair outcomes and it prevents a consistent decision policy. Segregating data reduces the amount of training data per model and can increase variance, and it does not address systemic biases or proxies that affect outcomes across groups.
Cloud DLP is incorrect because Cloud DLP is a data loss prevention service for discovering, classifying, and redacting sensitive information. It does not provide fairness evaluation metrics or bias mitigation techniques for model outcomes, so it does not solve the fairness validation problem.
Remove the race or ethnicity column from the training data is incorrect because simply dropping the sensitive attribute does not remove bias. Models can learn proxies for race from other features and removing the attribute prevents proper auditing and targeted mitigation. It is better to use the attribute to measure disparities and then apply appropriate mitigation.
When answering fairness questions focus on methods that include both measurement and mitigation. Avoid answers that suggest simply deleting sensitive attributes or relying on unrelated tools.
Which method executes the training code on Databricks and enables automated MLflow tracking during hyperparameter tuning?
The correct option is CrossValidator or TrainValidationSplit.
CrossValidator or TrainValidationSplit are Spark MLlib model selection classes that run training across combinations of hyperparameters and evaluate models using cross validation or a train validation split. When you run these on Databricks with MLflow autologging enabled each fit and evaluation is executed as a training run and MLflow automatically records parameters metrics and artifacts for each candidate model. These classes therefore both run the training code and enable automated MLflow tracking during hyperparameter tuning.
ParamGridBuilder is incorrect because it only builds the grid of hyperparameter values. It does not execute training or coordinate evaluation by itself and is used in combination with CrossValidator or TrainValidationSplit rather than replacing them.
MLflow Projects is incorrect in this context because Projects package and reproduce experiment runs and they can launch runs on Databricks, but they are not the Spark model selection mechanisms that orchestrate hyperparameter search within a pipeline. Projects are useful for reproducible runs but they are not the component that performs the cross validation or train validation splitting and automated per-trial logging in the same way that CrossValidator or TrainValidationSplit do.
When a question asks which component “runs” training look for pipeline or estimator classes that perform fitting. Remember that ParamGridBuilder builds values and MLflow Projects packages runs, while CrossValidator and TrainValidationSplit execute the training and evaluation steps that trigger autologging.
Cameron McKenzie is an AWS Certified AI Practitioner, Machine Learning Engineer, Copilot Expert, Solutions Architect and author of many popular books in the software development and Cloud Computing space. His growing YouTube channel training devs in Java, Spring, AI and ML has well over 30,000 subscribers.
OpenAI telah meminta pemerintahan Trump untuk memperluas kredit pajak besar dari UU CHIPS untuk mendukung pembangunan infrastruktur AI, termasuk server, pusat data, dan sistem tenaga. Perusahaan tersebut mengajukan proposal tersebut pada bulan Oktober sebagai bagian dari konsultasi publik Kantor Kebijakan Sains dan Teknologi mengenai kebijakan AI jangka panjang, menurut dokumen kebijakan yang diposting online oleh OpenAI.
Yang dipermasalahkan adalah Kredit Investasi Manufaktur Lanjutan (AMIC), kredit pajak investasi sebesar 25% yang dibuat berdasarkan Bagian 48D Kode Pendapatan Internal. Diselesaikan oleh Departemen Keuangan pada tahun 2024, kredit tersebut saat ini berlaku untuk belanja modal yang terkait dengan manufaktur dan perkakas semikonduktor. OpenAI mendesak pemerintah untuk memperluas cakupan tersebut, dengan alasan bahwa insentif yang sama harus diterapkan pada produksi server AI dalam negeri, serta pembangunan pusat data AI dan infrastruktur jaringan pendukung.
Perusahaan ini menggambarkan ekspansi ini sebagai cara untuk menurunkan biaya modal untuk infrastruktur AI yang berbasis di AS, mempercepat jadwal penerapan, dan memperkuat rantai pasokan yang sudah berada di bawah tekanan. Pengajuan tersebut secara khusus menyebut trafo tegangan tinggi, konverter HVDC, dan saluran transmisi sebagai hambatan jangka panjang yang memerlukan dukungan federal. Laporan ini juga merekomendasikan hibah tambahan, pinjaman, dan jaminan pinjaman untuk memastikan komponen-komponen penting diproduksi dalam skala yang memadai.
Permintaan OpenAI muncul di tengah perebutan industri yang lebih luas untuk mengamankan listrik, perangkat keras, dan real estat untuk kluster inferensi berskala besar. CEO Sam Altman sebelumnya mengatakan AS perlu menambah kapasitas generasi baru hingga 100 gigawatt untuk mendukung pertumbuhan AI, hampir dua kali lipat rencana perluasan jaringan listrik saat ini. Proyek pusat data generasi berikutnya dari perusahaan tersebut, yang kabarnya diberi nama “Stargate,” dapat menyedot daya hingga 5 gigawatt jika digunakan sendiri.
Meskipun Departemen Keuangan mempunyai keleluasaan dalam menafsirkan undang-undang tersebut, ruang lingkup AMIC saat ini ditentukan oleh Kongres. Memperluas kredit pajak untuk mencakup pusat data dan sistem AI kemungkinan memerlukan tindakan legislatif. Hal ini tidak menghentikan para pemimpin industri untuk melobi kelayakan yang lebih luas, terutama ketika AS berupaya mengimbangi ekspansi infrastruktur di Tiongkok dan negara-negara Teluk.
Dorongan untuk kredit pajak terpisah dari diskusi seputar jaminan pinjaman federal. Setelah reaksi publik atas laporan bahwa OpenAI telah menjajaki dukungan pemerintah untuk operasinya sendiri, Altman mengklarifikasi bahwa perusahaan tersebut hanya mencari jaminan dari mitra manufaktur semikonduktor. Pengajuan kebijakan tersebut tidak meminta subsidi langsung kepada OpenAI dan malah menguraikan langkah-langkah yang dapat memberikan manfaat bagi infrastruktur AI AS secara lebih luas.
Mengikuti Perangkat Keras Tom di Google Beritaatau tambahkan kami sebagai sumber pilihanuntuk mendapatkan berita, analisis, & ulasan terbaru kami di feed Anda.
Dapatkan berita terbaik dan ulasan mendalam Tom's Hardware, langsung ke kotak masuk Anda.
Guidewire software (GWRE) baru saja memperkenalkan platform PricingCenter barunya, yang dirancang untuk membantu perusahaan asuransi memperbarui strategi penetapan harga dengan lebih cepat dan akurat. Selain itu, perusahaan memperluas kemitraan One Inc. untuk menyederhanakan pembayaran klaim digital bagi perusahaan asuransi Kanada.
Lihat analisis terbaru kami untuk Perangkat Lunak Guidewire.
Peluncuran Guidewire baru-baru ini telah membantu menjaga momentum membangun saham. Pengembalian harga saham year-to-date sebesar 28,64% menunjukkan optimisme investor terhadap inovasi cloud dan kemitraan strategisnya. Meskipun terjadi penurunan jangka pendek selama sebulan terakhir, total pengembalian pemegang saham dalam satu tahun sebesar 11,86% dan total pengembalian tiga tahun yang luar biasa sebesar 257,85% menyoroti kekuatan dari kisah jangka panjangnya.
Jika Anda penasaran dengan apa yang dilakukan perusahaan-perusahaan teknologi dan berbasis AI terkemuka lainnya saat ini, ada baiknya Anda menjelajahi para pemimpin di bidangnya melalui kami. Lihat daftar lengkapnya secara gratis.
Dengan kinerja yang kuat dan inovasi baru yang masih berlangsung, pertanyaan besarnya saat ini adalah apakah penilaian Guidewire saat ini memberikan ruang untuk kenaikan lebih lanjut, atau apakah investor sudah memperhitungkan prospek pertumbuhan di masa depan.
Menurut narasi yang paling banyak diikuti, nilai wajar Guidewire diperkirakan jauh di atas harga penutupan terakhir sebesar $218,04. Hal ini menunjukkan bahwa terdapat potensi keuntungan yang belum dimanfaatkan berdasarkan metrik berwawasan ke depan dan pendorong pertumbuhan. Hal ini membuka peluang untuk melihat lebih dekat tema-tema strategis yang mendorong prospek bullish tersebut.
“Kesepakatan migrasi cloud selama 10 tahun yang penting dengan Liberty Mutual berfungsi sebagai validasi signifikan atas strategi cloud dan positioning pasar Guidewire, yang semakin meningkatkan kepercayaan terhadap momentum cloud yang berkelanjutan.Pengenalan panduan FY26 oleh manajemen dengan titik tengah untuk pendapatan, ARR, dan pendapatan operasional jauh di atas konsensus dan perkiraan sebelumnya memberikan visibilitas dan mendukung revisi target ke atas.”
Baca narasi lengkapnya.
Ingin tahu apa yang mendorong nilai wajar premi tersebut? Narasinya bergantung pada pertumbuhan pendapatan yang ambisius, lompatan margin yang berani, dan kelipatan laba yang agresif. Proyeksi ini mengisyaratkan perpaduan antara optimisme analis dan perkiraan agresif yang tidak boleh Anda lewatkan. Dapatkan rincian lengkapnya sebelum pasar menangkapnya.
Hasil: Nilai Wajar $268,38 (UNDERVALUED)
Bacalah narasinya secara lengkap dan pahami apa yang ada di balik ramalan tersebut.
Namun, risiko tetap ada. Kendala dalam pelaksanaan migrasi cloud dan nilai tukar mata uang asing yang tidak dapat diprediksi dapat menjadi tantangan bagi jalur Guidewire menuju pertumbuhan pendapatan yang berkelanjutan.
Cari tahu tentang risiko utama narasi Perangkat Lunak Guidewire ini.
Jika dilihat dari sudut pandang harga terhadap penjualan, Guidewire diperdagangkan dengan tingkat penjualan 15,4 kali lipat, yang jauh lebih tinggi dibandingkan rata-rata industri Perangkat Lunak AS sebesar 4,9x dan rata-rata industri sejenisnya sebesar 8,3x. Bahkan dibandingkan dengan rasio wajarnya sebesar 6,9x, saham tersebut terlihat mahal, sehingga menimbulkan risiko penilaian yang besar jika ekspektasi pasar berubah.
Lihat apa yang ditunjukkan angka-angka tentang harga ini — cari tahu di rincian penilaian kami.
NYSE:GWRE PS
Jika Anda melihat ceritanya secara berbeda atau ingin menggali sendiri angka-angkanya, Anda dapat menyusun perspektif Anda sendiri hanya dalam beberapa menit. Lakukan dengan caramu
Titik awal yang baik untuk riset Perangkat Lunak Guidewire Anda adalah analisis kami yang menyoroti 2 imbalan utama dan 1 tanda peringatan penting yang dapat memengaruhi keputusan investasi Anda.
Jangan puas mengikuti orang banyak ketika Anda bisa melihat peluang yang baru saja terjadi di pasar. Berikan energi pada portofolio Anda dan manfaatkan tren yang mungkin terlewatkan oleh investor lain. Simply Wall Street's Screener adalah kunci Anda menuju ide-ide paling cerdas saat ini.
Artikel oleh Simply Wall St ini bersifat umum. Kami memberikan komentar berdasarkan data historis dan perkiraan analis hanya dengan menggunakan metodologi yang tidak memihak dan artikel kami tidak dimaksudkan sebagai nasihat keuangan. Ini bukan merupakan rekomendasi untuk membeli atau menjual saham apa pun, dan tidak mempertimbangkan tujuan Anda, atau situasi keuangan Anda. Kami bertujuan untuk memberikan Anda analisis terfokus jangka panjang yang didorong oleh data fundamental. Perhatikan bahwa analisis kami mungkin tidak memperhitungkan pengumuman perusahaan terbaru yang sensitif terhadap harga atau materi kualitatif. Simply Wall St tidak memiliki posisi di saham mana pun yang disebutkan.
Perusahaan yang dibahas dalam artikel ini termasuk GWRE.
Punya tanggapan tentang artikel ini? Khawatir dengan isinya? Hubungi kami secara langsung. Atau, kirim email ke editorial-team@simplywallst.com
SanDisk dilaporkan telah menaikkan harga kontrak flash NAND secara mengejutkan sebesar 50% untuk bulan November, menurut DigiTimes Asia. Langkah ini menggarisbawahi pengetatan pasar memori yang pesat, didorong oleh permintaan yang tiada henti dari pusat data AI serta terbatasnya pasokan wafer.
Laporan tersebut mengutip sumber pasar yang mengatakan pembaruan harga SanDisk mengirimkan gelombang kejutan melalui rantai pasokan penyimpanan, mendorong pembuat modul seperti Transcend, Innodisk, dan Apacer Technology untuk menghentikan sementara pengiriman dan mengevaluasi kembali penawaran harga. Transcend, khususnya, menangguhkan kuotasi dan pengiriman mulai tanggal 7 November, mengantisipasi “kondisi pasar yang terus menguntungkan”. Terjemahan: “harga kemungkinan besar akan naik sebelum harga stabil.”
Jika Anda ingin gambaran betapa populernya bisnis memori, lihat angka-angkanya:
Transcend melaporkan pendapatan konsolidasi Q3 tahun 2025 sebesar NT$4,11 miliar (US$133 juta) — naik 27% kuartal-ke-kuartal dan 63% tahun-ke-tahun — dengan margin kotor mencapai 45%. Laba bersih melonjak 334% dibandingkan tahun lalu.
Innodisk tampaknya mengalami peningkatan pendapatan sebesar 64% dibandingkan tahun lalu menjadi NT$3,8 miliar (US$123 juta), dengan laba bersih naik hampir 250%.
Apacer Technology tampaknya juga tidak ketinggalan, meraup NT$3,22 miliar (US$104 juta) pada kuartal ketiga, naik 70% dari tahun lalu.
Baik produk DRAM maupun memori flash terpengaruh oleh lonjakan harga. (Kredit gambar: Innodisk)
Ketiganya memuji kinerja mereka berkat konsentrasi pasokan di pabrik wafer, yang memprioritaskan produksi DRAM bermargin tinggi, seperti DDR5 dan HBM (Memori Bandwidth Tinggi), untuk server AI dan peralatan komputasi berkinerja tinggi. Masalahnya: produk-produk DDR4 lama – yang masih penting untuk sistem industri dan perusahaan – kini persediaannya lebih sedikit, sehingga semakin meningkatkan harga di sektor hilir.
Ini adalah cerita yang sama yang kita lihat di industri chip sepanjang tahun: beban kerja AI menyedot udara keluar dari ruangan. Fabs mendedikasikan lebih banyak lini pada memori mutakhir untuk GPU dan akselerator, sehingga segmen komoditas seperti SSD konsumen, modul tertanam, dan DDR4 mainstream menjadi pendek. Hasilnya? Kekurangan struktural yang meningkatkan keuntungan bagi vendor memori sekaligus membuat OEM dan pengguna akhir kebingungan. Waktu Digi mencatat bahwa Transcend memperkirakan “momentum peningkatan” di pasar akan bertahan karena perusahaan menyeimbangkan kenaikan harga dengan kapasitas produksi yang terbatas.
Jika Anda berpikir untuk meningkatkan perangkat Anda atau memperluas kapasitas pusat data Anda, mungkin ini saatnya untuk segera mengambil tindakan. Antara kenaikan flash NAND SanDisk dan kekurangan DRAM yang terus berlanjut, harga SSD dan modul memori hanya mengalami tren satu arah, dan tidak turun. Sejarah menunjukkan bahwa ketika pembuat memori mencium keuntungan, mereka tidak terburu-buru menambah pasokan dalam semalam. Dengan AI yang masih menghabiskan setiap chip cadangan yang dapat dibuat oleh industri, kekurangan ini dapat berlanjut hingga tahun 2026 – kecuali gelembung AI tiba-tiba muncul, namun perekonomian kita akan menghadapi hal-hal yang lebih besar yang perlu dikhawatirkan.
Mengikuti Perangkat Keras Tom di Google Beritaatau tambahkan kami sebagai sumber pilihanuntuk mendapatkan berita, analisis, & ulasan terbaru kami di feed Anda.
Dapatkan berita terbaik dan ulasan mendalam Tom's Hardware, langsung ke kotak masuk Anda.
Mereka yang ingin membangun rig menara menengah bisa mendapatkan casing ruang ganda iCUE Link 2500X dari Corsair dengan diskon besar-besaran. Dengan MSRP terdaftar sebesar $219,99, Anda bisa mendapatkan varian putih hanya dengan $59,99 di Newegg. Intinya, Anda menghemat lebih dari 70%, dan jika Anda menginginkan aliran udara yang lebih baik, varian panel jaring depan juga tersedia dengan harga diskon yang sama.
Corsair iCUE Link 2500X dapat mengakomodasi motherboard back-connect m-ATX dan mini-ITX (Asus BTF, MSI Project Zero), memungkinkan Anda menjaga pengaturan tetap bersih dan bebas dari kekacauan. Muncul dengan dua kipas RGB 120mm yang sudah terpasang dan mendukung hingga kipas 9x 120mm atau 4x 140mm, dengan opsi untuk memasang radiator 240mm atau 360mm. Varian Airflow tidak dilengkapi dengan kipas pra-instal tetapi menawarkan dukungan yang lebih luas hingga kipas 11 x 120mm dan 6 x 140mm, ditambah opsi pemasangan tambahan untuk radiator 240mm di bagian depan.
Dalam hal I/O depan, casing ini dilengkapi dengan dua port USB 3.2 Gen 1 Tipe-A, port USB 3.2 Gen 2 Tipe-C, dan jack kombo headphone/mikrofon. Casing ini juga dapat menampung dua SSD 2,5 inci dan dua HDD 3,5 inci, catu daya ATX ukuran penuh dengan panjang hingga 225mm, dan tinggi pendingin CPU maksimum 180mm. Memungkinkan Anda memasang GPU berukuran terbesar hingga 400mm, Corsair juga menjual kit pemasangan vertikal secara terpisah untuk casing ini. Selain itu, perusahaan menjual panel aksen yang dapat ditukar untuk sepenuhnya mengubah estetika bangunan Anda, tersedia dalam bahan kayu atau aluminium.
Berdasarkan pengalaman kami, kami menemukan bahwa casing ini memberikan dukungan luar biasa untuk motherboard konektor belakang yang lebih baru dan manajemen kabel yang sangat baik, meskipun harganya jelas tidak membuat kami terkesan. Untungnya, dengan penjualan ini, Anda bisa mendapatkan salah satu varian dengan harga yang jauh lebih baik.
Jika Anda mencari lebih banyak penghematan, lihat kami Penawaran Perangkat Keras PC terbaik untuk berbagai produk, atau selami lebih dalam spesialisasi kami Penawaran SSD dan Penyimpanan,Penawaran Hard Drive, Penawaran Monitor Gaming, Penawaran Kartu Grafisatau Penawaran CPU halaman.
monday.com (MNDY) menarik perhatian investor setelah laporan pendapatan terbarunya menunjukkan pendapatan kuartalan melebihi ekspektasi, bersamaan dengan komentar positif manajemen mengenai efisiensi operasional dan momentum pertumbuhan berkelanjutan di masa depan.
Lihat analisis terbaru kami untuk monday.com.
Setelah tahun rollercoaster yang mencakup pergerakan triwulanan yang menonjol dan beberapa penurunan tajam, harga saham monday.com saat ini berada di $189,59. Naik turunnya jangka pendek, seperti kenaikan satu hari sebesar 4,73% dan penurunan tajam sebesar 7,63% selama seminggu terakhir, kontras dengan total pengembalian pemegang saham dalam 1 tahun yang jauh lebih curam yaitu -41,54%. Namun, pemegang saham jangka panjang masih melipatgandakan uang mereka, karena total pengembalian dalam 3 tahun mencapai 99,17%. Momentum nampaknya mulai terbangun kembali setelah melewati masa-masa sulit di awal tahun.
Jika pergeseran momentum dan kisah pertumbuhan menarik minat Anda, ini bisa menjadi peluang sempurna untuk menemukan saham-saham yang tumbuh cepat dengan kepemilikan orang dalam yang tinggi.
Dengan pertumbuhan pendapatan yang kuat dan prospek manajemen yang optimis, investor kini menghadapi pertanyaan penting: Apakah monday.com masih dinilai terlalu rendah pada level saat ini, atau apakah pasar sudah memperhitungkan semua potensi keuntungan di masa depan?
Narasi Paling Populer: 28,8% Diremehkan
Estimasi nilai wajar saat ini sebesar $266,33 berada jauh di atas penutupan terakhir Monday.com di $189,59, menandakan narasi utama memandang kenaikan besar di masa depan. Apa yang mendorong skenario optimis ini? Lihat apa yang disoroti oleh analisis yang paling banyak diikuti sebagai katalis utama untuk keuntungan di masa depan.
Strategi multi-produk, dengan percepatan pertumbuhan vertikal CRM dan Layanan, memperluas total pasar yang dapat ditangani dan mendorong lebih banyak peluang cross-sell/upselling. Hal ini meningkatkan perluasan kursi dan ukuran transaksi rata-rata, sehingga menghasilkan pendapatan perusahaan yang lebih tinggi dan pertumbuhan pendapatan yang tahan lama. Momentum kelas atas dan rekor penambahan pelanggan perusahaan (lebih dari $100K ARR) menunjukkan penetrasi akun besar yang berkelanjutan. Hal ini meningkatkan visibilitas pendapatan berulang dan mendukung peningkatan margin melalui leverage operasi seiring dengan normalisasi penjualan dan investasi penelitian dan pengembangan.
Baca narasi lengkapnya.
Ingin mengetahui mengapa para analis begitu bullish? Tersembunyi di bawah angka utama ini adalah perkiraan pendapatan dan laba yang agresif, ditambah asumsi yang berani mengenai ekspansi margin jangka panjang dan pertumbuhan perusahaan. Bongkar proyeksi kontroversial yang mendasari estimasi nilai wajar ini.
Hasil: Nilai Wajar $266,33 (UNDERVALUED)
Bacalah narasinya secara lengkap dan pahami apa yang ada di balik ramalan tersebut.
Namun, peningkatan margin yang berkelanjutan dapat terhambat jika penambahan pelanggan melambat atau jika persaingan dari pesaing perangkat lunak yang lebih besar semakin ketat, sehingga dapat mengurangi prospek bullish.
Cari tahu tentang risiko utama narasi monday.com ini.
Bangun Narasi Monday.com Anda Sendiri
Jika Anda ingin mendalami lebih dalam dan mengambil kesimpulan sendiri, Anda dapat dengan cepat menghasilkan tampilan pribadi hanya dalam beberapa menit. Lakukan dengan caramu.
Titik awal yang baik adalah analisis kami yang menyoroti 3 penghargaan utama yang optimis bagi investor mengenai monday.com.
Mencari lebih banyak ide investasi?
Mengapa hanya puas dengan satu kesempatan saja? Kendalikan dan temukan saham-saham dengan potensi nyata menggunakan penyaring kami yang dikurasi oleh para ahli. Pemenang besar berikutnya mungkin hanya berjarak satu klik saja.
Artikel oleh Simply Wall St ini bersifat umum. Kami memberikan komentar berdasarkan data historis dan perkiraan analis hanya dengan menggunakan metodologi yang tidak memihak dan artikel kami tidak dimaksudkan sebagai nasihat keuangan. Ini bukan merupakan rekomendasi untuk membeli atau menjual saham apa pun, dan tidak mempertimbangkan tujuan Anda, atau situasi keuangan Anda. Kami bertujuan untuk memberikan Anda analisis terfokus jangka panjang yang didorong oleh data fundamental. Perhatikan bahwa analisis kami mungkin tidak memperhitungkan pengumuman perusahaan terbaru yang sensitif terhadap harga atau materi kualitatif. Simply Wall St tidak memiliki posisi di saham mana pun yang disebutkan.
Baru: Penyaring & Peringatan Saham AI
Penyaring Saham AI kami yang baru memindai pasar setiap hari untuk mengungkap peluang.
• Dividen Powerhouse (3%+ Hasil) • Saham Kecil yang Diremehkan dengan Pembelian Orang Dalam • Perusahaan Teknologi dan AI dengan pertumbuhan tinggi
Atau buat sendiri dari lebih dari 50 metrik.
Jelajahi Sekarang Gratis
Punya tanggapan tentang artikel ini? Khawatir dengan isinya? Hubungi kami secara langsung. Atau, kirim email ke editorial-team@simplywallst.com
Perangkat Lunak Ryzen AI sebagai kumpulan alat dan perpustakaan AMD untuk inferensi AI pada PC kelas AMD Ryzen AI memiliki dukungan Linux dengan rilis poin terbarunya. Meskipun dukungan Linux “akses awal” ini terbatas pada pelanggan AMD yang terdaftar.
Awal tahun ini kami melaporkan tentang AMD yang mempratinjau tumpukan runtime Linux baru untuk NPU Ryzen AI dan membangun driver akselerator kernel AMDXDNA mereka. Tampaknya hal tersebut kini dipaketkan ke dalam koleksi Perangkat Lunak Ryzen AI, yang sebelumnya hanya untuk Windows. Dengan rilis poin terbaru Perangkat Lunak AI Ryzen 1.6.1, satu-satunya perubahan yang dicatat dalam catatan rilis adalah dukungan Linux:
Dukungan Ryzen AI Linux dengan dukungan untuk aliran CNN, Transformer, dan LLM. Meskipun “Ryzen AI software Early Access Lounge” itulah yang kemudian mengirim Anda ke area masuk untuk pengembang/pelanggan terdaftar dengan AMD. Selain itu, saya tidak memiliki detail apa pun tentang dukungan Linux baru ini setelah mempelajarinya hari ini. Kemungkinan itu hanya dibangun dari driver akselerator kernel AMDXDNA hulu dan kemudian bit ruang pengguna seperti tumpukan Xilinx XRT. Agak konyol bahwa mereka terus menggunakan biner Linux yang telah dibuat sebelumnya hanya untuk mempersulit pengembang Linux untuk melibatkan dan akhirnya memanfaatkan NPU Ryzen AI di Linux.
Halaman dokumentasi ini mencatat Ubuntu 24.04 LTS sebagai satu-satunya distribusi Linux yang didukung secara resmi untuk Perangkat Lunak Ryzen AI.
Dukungan Linux dikatakan mendukung eksekusi NPU dan bekerja dengan model CNN dalam format INT8 atau BF16, model NLP dalam format BF16, dan LLM hanya untuk eksekusi berbasis NPU dan biasanya memerlukan memori sistem 64GB+.











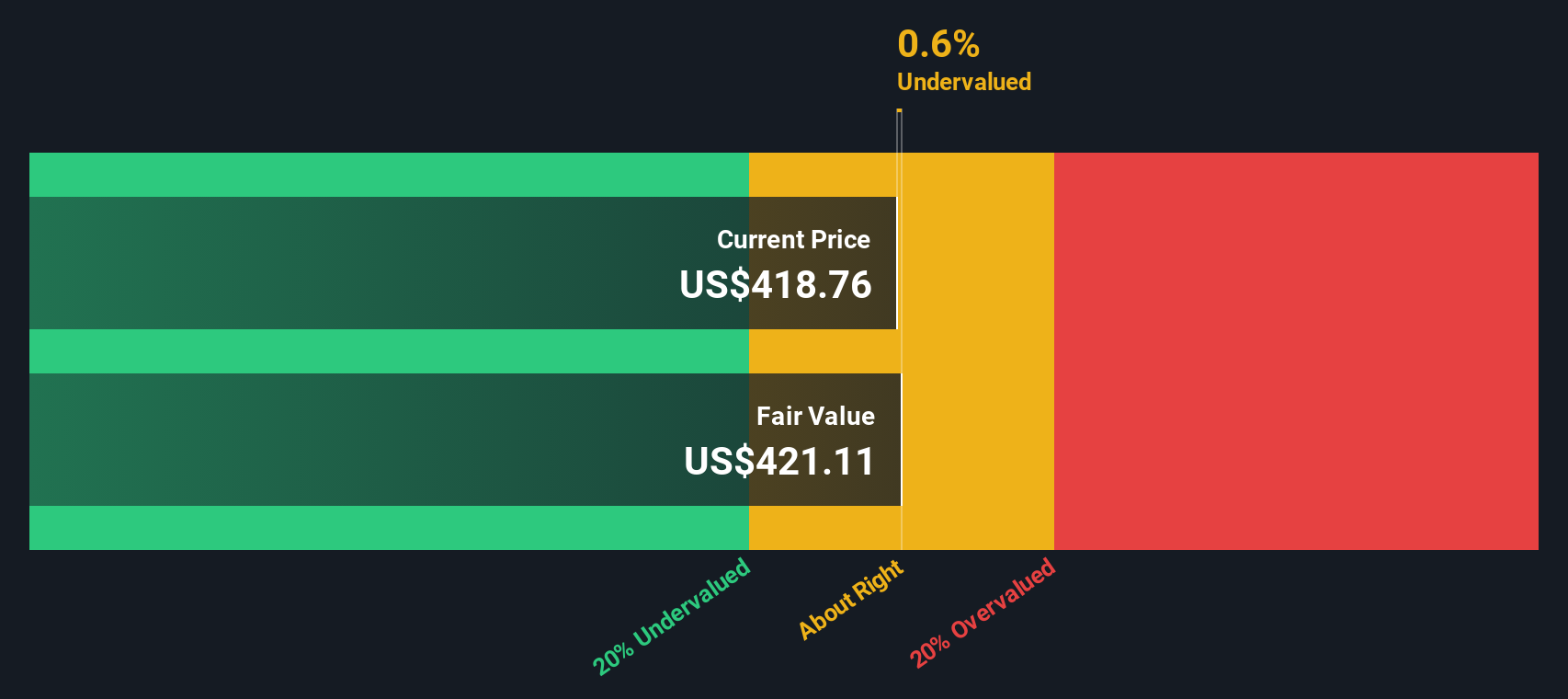
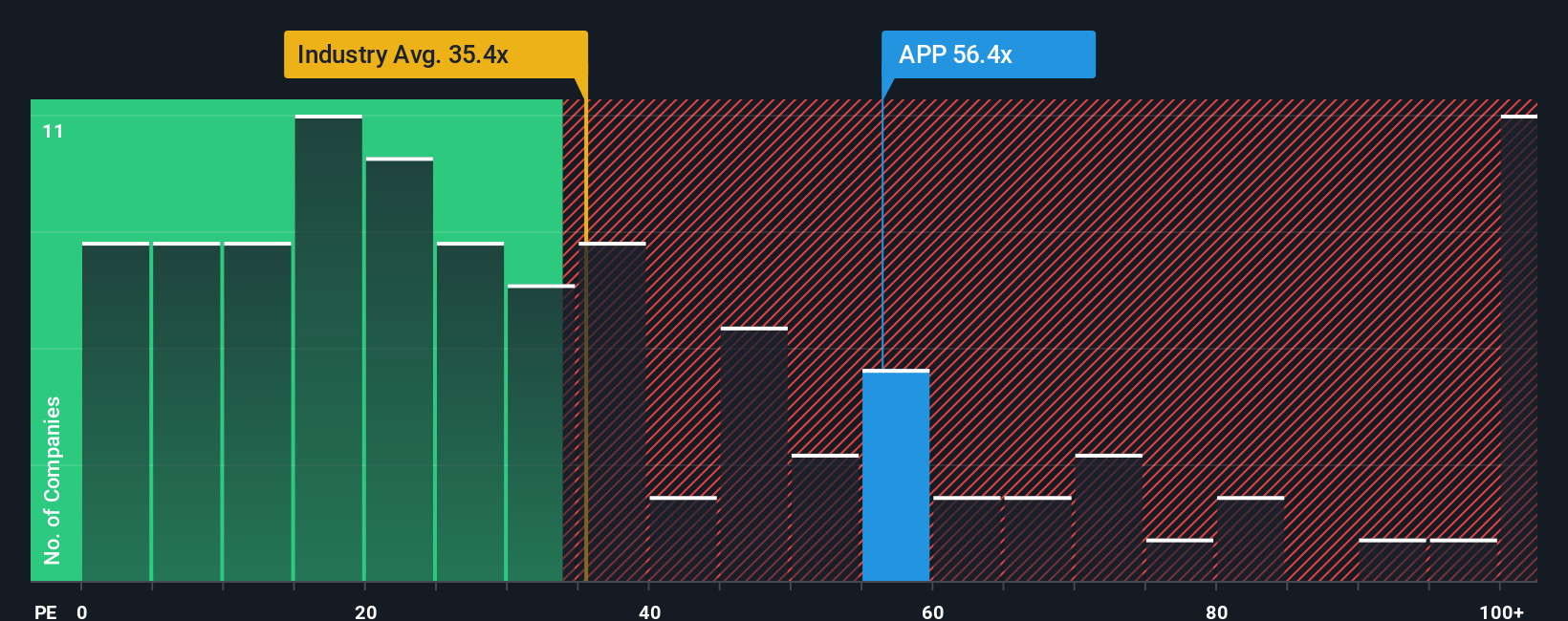
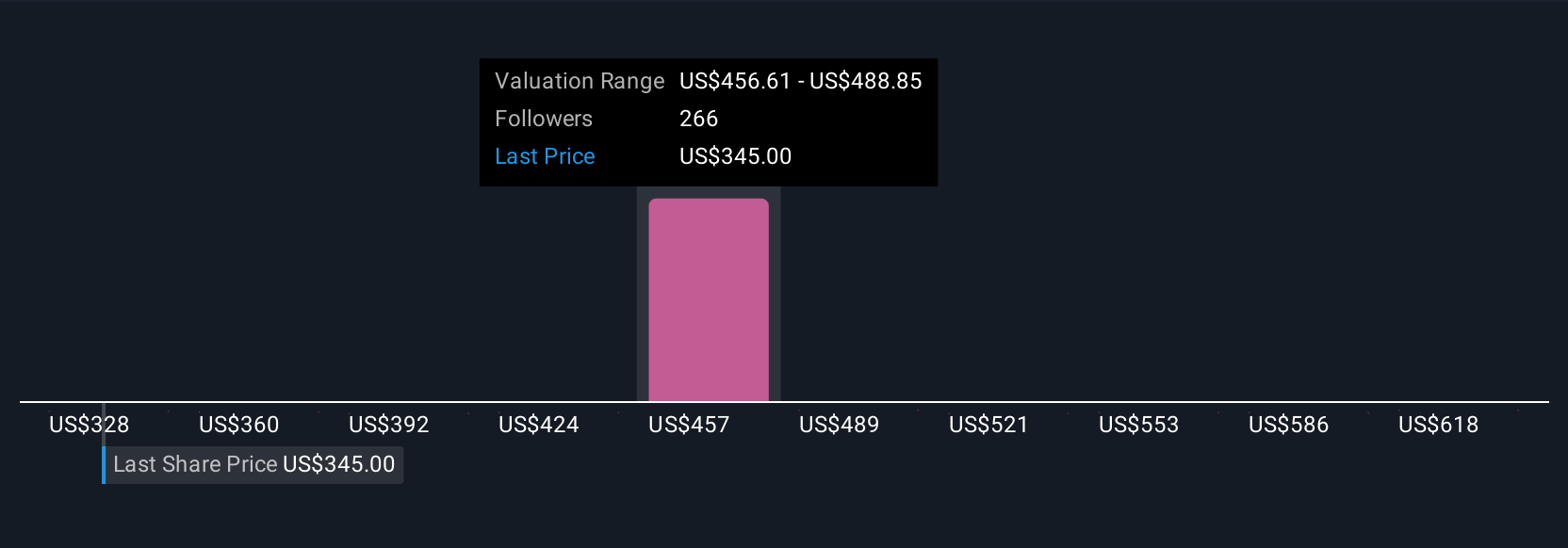

 media=”https://cdn.mos.cms.futurecdn.net/7cUTDmN2PHNRiNBVqbKf56.png” class=”pull-left”/>
media=”https://cdn.mos.cms.futurecdn.net/7cUTDmN2PHNRiNBVqbKf56.png” class=”pull-left”/>

 media=”https://cdn.mos.cms.futurecdn.net/e7AQSwomPwfGoniQHXDqTR.jpg” class=”expandable”/>
media=”https://cdn.mos.cms.futurecdn.net/e7AQSwomPwfGoniQHXDqTR.jpg” class=”expandable”/>
